Scalability Issues in CSRSS
Windows Research Kernel @ HPIOne of our current topics is pushing the limits of operating systems. Inspired by Mark Russinovich's article Pushing the Limits of Windows: Processes and Threads, we built a theoretical model for the amount of threads that can be created on a given system and then tried to reach these limits. However, the practical evaluation was kind of tricky and we stumbled upon an issue within CSRSS, Windows' client server runtime subsystem.
Limits on Threads
The maximum number of threads in a system is limited by various
resources. For example, on a 32-bit Windows system, the major
limitation is the address space of a process. As each thread
requires a certain number of memory in kernel space (NtCreateThread
- memory allocations in kernel mode) and user space, you can
easily calculate the number of threads you can create until the
address space of the process is exhausted. In contrast, on 64-bit
systems, the major limitation is not the address space, but the
physical amount of memory plugged into the machine. For each thread,
Windows allocates some memory in kernel space and also the thread
stack in user mode. Once the total physical memory on a machine
without paging is exhaustet, no further threads can be created.
Limitation by Physical Memory
The HPI recently established a laboratory - the Future SOC Lab
- with absolutely stunning hardware. We managed to get access to a
machine equipped with 64 cores and 1 TB of main memory to evaluate
our hypothesis that once we would have enough memory in the machine,
we could reach the theoretical limit.
So, how many threads could be created on such a machine? According
to our calculation model a thread on a 64-bit Windows Server 2008 R2
system consumes at least 50KB of memory - using a minimal stack.
Therefore we should be able to exceed the number of 20 million
threads, spread across multiple processes.
Limitation by Kernel Constants
Having a closer look into the WRK, we found out another limit. The
kernel itself holds a list of all process and thread IDs used in the
system. And this list is an ordinary handle table. So the maximum
size of 2^24 entries for a handle table also holds for the
process/thread ID table.
The constant is defined in base\ntos\ex\handle.c, Line 101:
#define MAX_HANDLES (1<<24)
Thus, the maximum number of threads in the whole system is limited to 16,777,216. So let's try to consume all those thread IDs.
First Tests
Here is our test setup: we wrote a little C program, which creates
as many threads as possible. Of course we created our threads only
with minimal stack sizes and and let Windows only reserve but not
commit stack allocations. Also, we started our threads only in a
suspended execution mode.
Our program tries to create threads in parallel. Therefore we start some dedicated threads that create as many threads as possible in a loop. The routine for the dedicated threads looks like:
DWORD WINAPI parallelCreateThreadFunc(LPVOID data) { HANDLE hThread; // create threads until errors occur while(hThread = CreateThread(NULL, 0, sleepThread, NULL, CREATE_SUSPENDED, NULL)) { // close the handle to keep the process-wide handle table clean CloseHandle(hThread); // count the created threads in a thread-safe manner InterlockedIncrement(&totalThreadCount); } return 0; }
On another test system with 4GB of main memory, we reached the maximum of about 90,000 threads in 5 seconds. On the big system we stumbled upon an issue: Our test program created the first million of threads in about some minutes. Continuing to the next million, our program needed almost an hour! That was strange, so we decided to investigate the matter a little bit further. Unfortunately, we could not investigate it on the big Future SOC Lab machine, as our access time was restricted. Nevertheless, we will demonstrate that our findings apply to the big machine as well.
First tests indicated that the time for creating a thread increases with every new thread, instead of being constant. A linear correlation between the number of created threads and the creation time was documented by further measurements. But where is the bottleneck?
CSRSS
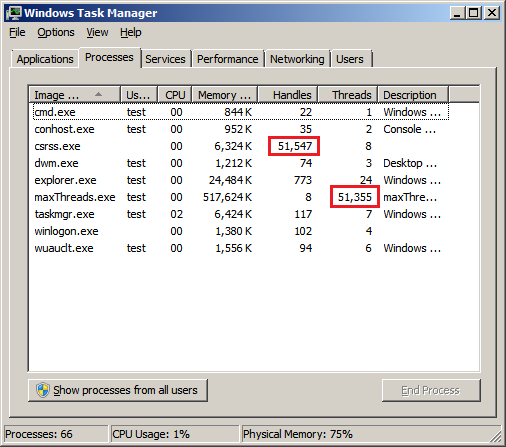
While starring at the taskmanager during our tests we noticed the
increasing number of open handles in the CSRSS process. The more
threads we created, the more handles showed up in Task Manager.
During thread creation the number of threads and the open handles in
CSRSS increased synchronously. But the reverse process, the
termination of these threads, was not synchronized. The CSRSS took
much more time for reducing the handle count towards zero. Maybe
there's the bottleneck. So what in the world is CSRSS doing?
The Windows Internals book told us that during process creation
CSRSS is informed and a function named
"CsrCreateProcess" is called via LPC. The Dependency
Walker shows for csrss.exe that the corresponding csrsrv.dll also
exports a function named "CsrCreateThread". So maybe
for thread creation something similar is going on.
Hash Table Full of Threads
In the WRK there are no sources for those DLLs. But the ReactOS project held some sources for
CSRSS. Of course the ReactOS code is not the one underlying to our
Windows Server 2008 R2, but the principles should be the same. The
sources (thread.c)
revealed that CSRSS maintains a hash table for threads inside of
csrsrv.dll. It is implemented as chained hash table with doubly
linked lists and only 256 buckets. Also, for every thread creation,
CSRSS makes a lookup for the ID of current thread to receive the
corresponding CSR_THREAD object.
Definition of the hash table in thread.c:
LIST_ENTRY CsrThreadHashTable[256];
Extract of the CsrCreateThread function in thread.c:
NTSTATUS NTAPI CsrCreateThread(IN PCSR_PROCESS CsrProcess, IN HANDLE hThread, IN PCLIENT_ID ClientId) { //... more code /* Get the current Process and make sure the Thread is valid with this CID */ CurrentThread = CsrLocateThreadByClientId(&CurrentProcess, &CurrentCid); //... more code }
Implementation of lookup function CsrLocateThreadByClientId in thread.c:
PCSR_THREAD NTAPI CsrLocateThreadByClientId(OUT PCSR_PROCESS *Process OPTIONAL, IN PCLIENT_ID ClientId) { ULONG i; PLIST_ENTRY ListHead, NextEntry; PCSR_THREAD FoundThread; /* Hash the Thread */ i = CsrHashThread(ClientId->UniqueThread); /* Set the list pointers */ ListHead = &CsrThreadHashTable[i]; NextEntry = ListHead->Flink; /* Star the loop */ while (NextEntry != ListHead) { /* Get the thread */ FoundThread = CONTAINING_RECORD(NextEntry, CSR_THREAD, HashLinks); /* Compare the CID */ if (FoundThread->ClientId.UniqueThread == ClientId->UniqueThread) { /* Match found, return the process */ *Process = FoundThread->Process; /* Return thread too */ return FoundThread; } /* Next */ NextEntry = NextEntry->Flink; } /* Nothing found */ return NULL; }
With millions of threads created that hash table would degenerate more or less into a simple list with linear search complexity. However, these findings are based on ReactOS, so we needed to verify that something similar is going on in Windows Server 2008 R2.
Drill Into Windows Server 2008 R2
We started WinDbg for inspecting our CSRSS. If you intend to follow
our experiment, be careful not to break into CSRSS in the same
session as your debugger runs, as otherwise the system will halt.
Debugging another session works fine. When using the debugging
symbols provided by Microsoft, the inspection was quite simple. We
could verify that there is still a hash table called
CSRSRV!CsrThreadHashTable with linked lists for its
buckets. The size of the hash table changed however in Windows
Server 2008 R2. We determined the actual size right from the
underlying hash function. In ReactOS this function was a simple
macro and in the disassembly the hashing algorithm was inlined in
many places.

The formula is: (ThreadID / 4) % 1024. Thus, the
hash table has 1024 buckets - but that's still too small. To prove
that this hash table has a significant impact on thread creation
time, we patched the hash algorithm into a constant function. So
every thread ID was placed into the first bucket of the hash table.
The time for creating a thread increased by an order of magnitude,
compared to our unpatched version. And indeed, on the small 4GB
machine the creation process extremely slowed down.
So we could prove that the performance degradation correlates to
CSRSS's hash table, which means that we found the bottleneck. But
how can we fix this?
Working Around the Scalability Issues
We had three alternatives: either increasing the number of hash
table entries, replacing the hash table with another data structure,
or not using it at all. As we lack the sources of CSRSS, we decided
for the latter. In this regard, we were not fixing the issue but
rather working around to see if our assumptions were correct.
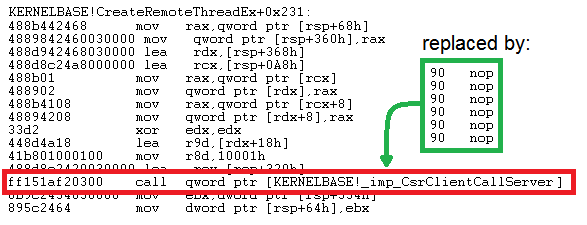
We extended our test program so that it patches the WinAPI
CreateThread function in memory in order to avoid any
LPC calls to CsrCreateThread. Therefore, we replaced
the call instruction in the kernel32 module (more precisely:
kernelbase.dll) at the right offset with NOP instructions. But
beware of changes in global shared memory without activating
copy-on-write for the corresponding pages.
Surprisingly, this quick and dirty hack worked very well and
everything went as before except that CSRSS wasn't informed about
newly created threads. Though, we must admit that we don't know
about all the implications of our modification. Maybe, if we would
use "real working" threads instead of "sleeping" threads, something
might fail.
However, thread creation was fast, really fast. Within seconds we
created 4.7 million threads - maybe more than anyone did before. We
will provide detailed results of our performance measurements
soon.
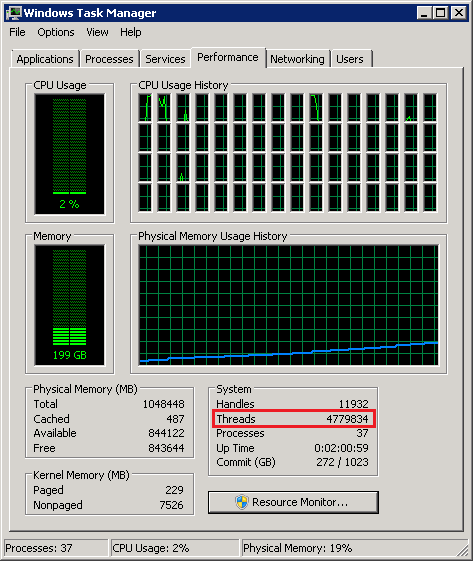
In conclusion, we could verify that CSRSS is having scalability issues upon thread creation, specifically when there are millions of those. Also, we ran into yet another limitation, which we have not been able to resolve yet. We could only create 4.7 millions of threads but not 16 millions. As soon as we figured out that limitation, we will post it here.
Comments
One Response to "Scalability Issues in CSRSS"
That was a good read - nice work.