Measuring Spin-Locks
Windows Research Kernel @ HPIInspired by work of Thomas Friebel on Lock-Holder Preemption we did some experiments with the Windows Research Kernel:
- How can we measure the time a thread is spinning while waiting for a spin-lock?
- Does lock-holder-preemption occur on Windows systems (using VMware Workstation)?
Unfortunately, we could not boot the WRK with Xen. Therefore, the results of our initial experiments which are described in this post can not be compared directly to the work done by Thomas Friebel in the Linux/Xen environment.
In the Linux-Kernel source code, spin-locks are wrapped in a
handful of
functions. Therefore, the instrumentation of spin-locks is
relatively easy. The WRK spin-lock implementation (for 32bit x86
kernels) relies on the assembler macros ACQUIRE_SPINLOCK and
SPIN_ON_SPINLOCK defined in \base\ntos\inc\mac386.inc.
These macros are used for several spin-lock functions in several
source code files. This makes the instrumentation slightly more
difficult.
ACQUIRE_SPINLOCK macro LockAddress, SpinLabel lock bts dword ptr [LockAddress], 0 ; test and set the spinlock jc SpinLabel ; spinlock owned, go SpinLabe endm SPIN_ON_SPINLOCK macro LockAddress, AcquireLabel local a a: test dword ptr [LockAddress], 1 ; Was spinlock cleared? jz AcquireLabel ; Yes, go get it YIELD jmp short a endm
The labels AcquireLabel and SpinLabel
are passed as parameters to the macro. Examples for the usage of
these macros can be found in
\base\ntos\ke\i386\spinlock.asm.
cPublicProc _KeAcquireSpinLockAtDpcLevel, 1 cPublicFpo 1,0 mov ecx,[esp+4] ; SpinLock aslc10: ACQUIRE_SPINLOCK ecx,<short aslc20> stdRET _KeAcquireSpinLockAtDpcLevel aslc20: SPIN_ON_SPINLOCK ecx,<short aslc10> stdRET _KeAcquireSpinLockAtDpcLevel stdENDP _KeAcquireSpinLockAtDpcLevel
The spin-lock address is passed on the stack and is saved in the
ecx register. Now, ACQUIRE_SPINLOCK is
used with aslc20 as spin label. If the spin-lock could
not be acquired, the code at aslc20 is executed - and
the SPIN_ON_SPINLOCK macro jumps back to
aslc10. The code block between the two macros is
executed when the spin-lock was acquired successfully.
What we want to measure in our experiment is, how long it takes
to acquire a spin-lock successfully. Therefore, we need to save a
time stamp before the first execution of
ACQUIRE_SPINLOCK and a time stamp after the spin-lock
is acquired (before the first stdRET
_KeAcquireSpinLockAtDpcLevel statement in the above
example).
We decided to store the time counters in an array which is
referenced in the PRCB (processor control block). A
unique PRCB is assigned to each CPU in the system. The
array is allocated and initialized in
ExpInitializeExecutive
(\base\ntos\init\initos.c). This function is called for
every CPU in the system (Number parameter).
// // Initialize SpinLock Performance Data Array for current CPU // { UCHAR i; PKPRCB Prcb = KeGetCurrentPrcb(); DbgPrint("[SpinLockPerf] initialize spinlock performance data array - cpu #%d\n", Number); Prcb->SpinLockPerfData = ExAllocatePoolWithTag(NonPagedPool, 32*sizeof(ULONG), 'DPLS'); for(i=0; i<32; ++i) { Prcb->SpinLockPerfData[i] = 0; } }
The first entry in the array is used to store the start time
stamp of a single measurement, the second entry is used as an
overflow counter. The remaining entries are used to store counters
for different ranges of cycles required to acquire spin-locks. The
following code snippet shows parts of the instrumented
KiAcquireSpinLock function.
[...] pushad ; save registers mov edi, fs:PcPrcb ; get PRCB mov edi, [edi].PbSpinLockPerfData ; get spinlock performance counter array cpuid ; serialize execution ;; ### start measurement rdtsc ; read time stamp counter mov [edi], eax ; save low part of tsc in first field popad ; restore registers asl10: ACQUIRE_SPINLOCK ecx,<asl20> pushad ; save registers cpuid ; serialize execution rdtsc ; read time stamp counter ;; ### stop measurement mov edi, fs:PcPrcb ; get PRCB mov edi, [edi].PbSpinLockPerfData ; get spinlock performance counter array sub eax, [edi] ; subtract old tsc value from new value jo overflow ; counter overflow? -> skip bsr ebx, eax ; determine most significant bit shl ebx, 2 ; calculate array entry -> multiply 4 add edi, ebx ; set edi to array entry add [edi], 1 ; increase array entry jmp done ; done overflow: add [edi+4], 1 ; increment overflow counter (second field in array) done: popad ; restore registers [...]
We use the most significant bit of the difference of the time
stamps as index in the counter array. Therefore, the value in
SpinLockPerfData[8] counts how often a thread needed
between 128 (10000000b) and 255 (11111111b) cycles to successfully
acquire a spin-lock; the value in SpinLockPerfData[9]
counts how often a thread needed between 256 (100000000b) and 511
(111111111b) cycles. As you can see, the resolution gets coarser for
higher wait times.
Additional to the described spin-lock instrumentation, we implemented a system service call for accessing the gathered spin-lock counter data from user-mode. Note that we gather data for each CPU. Therefore, the user-mode program combines the data.
With this infrastructure in place, we can measure the duration of acquire operations on spin-locks. For experiments, we used a workstation with Intel Core2 Duo CPU (3 GHz, 4 GByte RAM) and the modified Windows Research Kernel (booted natively, not in a virtual machine).
We used the WRK build environment as workload: The WRK source tree was compiled (and cleaned afterwards) once. Using this system, we could measure the following results:
| cycles | count | % |
| 2^ 6 | 0 | |
| 2^ 7 | 135 | 00.19 |
| 2^ 8 | 67749 | 98.06 |
| 2^ 9 | 1200 | 01.74 |
| 2^10 | 3 | |
| 2^11 | 1 | |
| 2^12 | 0 |
In short, almost all acquire operations for spin-locks required
between 128 and 255 cycles (minus the cycles required for
measurement: 2x rdtsc, 1x mov, 1x
cpuid, 1x pushad, 1x popad).
No spin-lock could be acquired in less than 2^7 cycles. No overflow
(rdtsc low part) occured.
In virtualized environments, the problem of lock-holder-preemption may occur: If a virtual machine uses multiple virtual CPUs which synchronize via spin-locks, the virtual machine monitor (or hypervisor) might preempt a (spin-)lock-holding-CPU and schedule another virtual CPU. In such a scenario, a virtual CPU which wants to acquire this particular spin-lock just burns CPU cycles because the spin-lock can not be acquired before the preempted CPU is scheduled again.
We tried to produce such an effect by running the instrumented
WRK in a virtual machine with two virtual CPUs. On the host system,
we executed a compute bound while(true) ; loop (on each
physical CPU).
Even in a virtualized environment, almost all spin-lock wait times requires 2^8 cycles. The picture shows the cumulative distribution function of the measurement results without host workload.
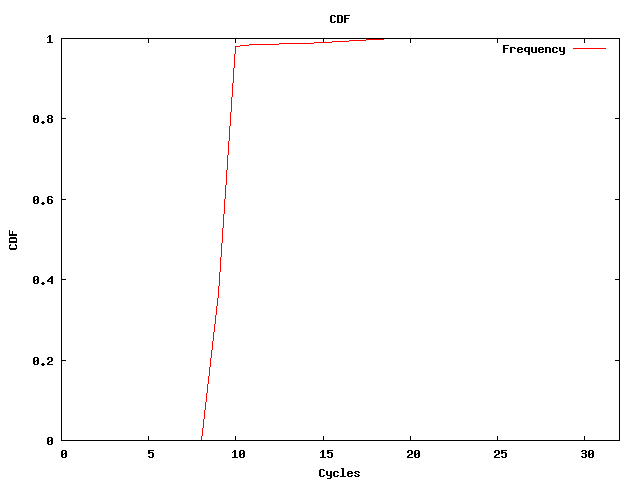
If we run concurrent workload on the host system, lock-holder-preemption might happen. Indeed, the CDF shows some differences:
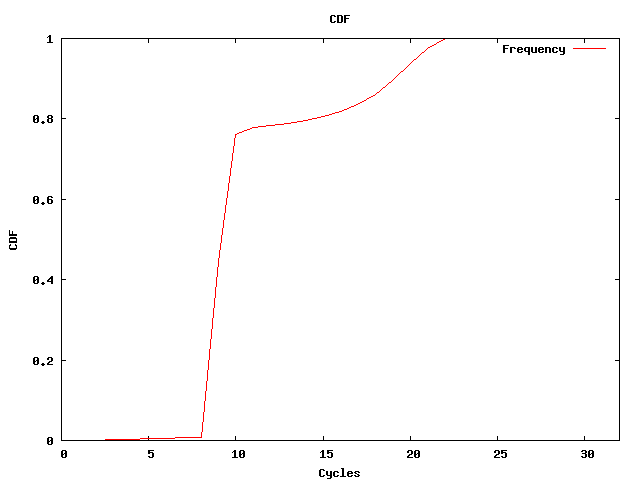
Still, ~ 80% of all spin-lock acquire operations needed less than 2^8 cycles. Very few acquire operations needed more than 2^20 cycles. The value distribution shows a different picture compared to the results published by Thomas Friebel for the Linux/Xen environment.
But …
… there are several open issues with our WRK implementation:
- We used VMware Workstation as virtualization envrionment. The isolation between virtual machine and host system is weak, compared to Xen and other "real" hypervisors.
- We instrumented only a few spin-lock functions of the Windows Research Kernel. Maybe we missed the one important function which will be preempted many times in a virtualized setting.
Therefore, we will do further measurements on other virtualization platforms, such as VMware ESXi (or Xen if we resolve the WRK boot problem).
Comments
6 Responses to "Measuring Spin-Locks"
Hi Michael,
Interesting post! Especially that most waits are shorter than 2^9 cycles. Under Linux we saw most of the waits between 2^9 and 2^14 cycles - and generally a wider range. My guess is that Linux uses spinlocks when it should/could use sleeping locks instead.
I am curious if you find additional spinlock uses in the WRK that change the picture.
Kind regards
…and be aware of the time source. Generally you can't trust virtualized time.
Good point. Do you know reliable alternatives to RDTSC? 🙂
I don't know how to solve this with VMware.
But using Xen you can setup a PMC to count guest cycles, and modify Xen to not intercept the RDPMC instruction. And you need to save/restore that PMC when switching VCPUs… At least that is what worked for me. 🙂
These snippets look worse than the Assembly language code I worked on in college… I'm just glad I'm over the course.
excellent post