Dr. GUI on Components, COM, and ATL
Contents
Part 1: You're Gonna Do COM? Hasn't It
Been Done Already? (February 2, 1998)
Part 2: Basics of COM (February 9, 1998)
Part 3: Getting Objects and
Interfaces (February 23, 1998)
Part 4: The Class Object and Class
Factory (March 2, 1998)
Part 5: Implementing an Object (March 30, 1998)
Part 6: Using Our COM Object in Visual Basic
and Visual J++ (April 27, 1998)
Part 7: Using Our Object from Visual
C++ (May 29, 1998)
Part 8: Get Smart! Using Our COM Object with
Smart Pointers (July 30, 1998)
Part 1: You're Gonna Do COM? Hasn't It Been Done Already?
The good doctor can hear you now: "You're gonna do what? Explain COM? Books have been written on that subject!"
Indeed they have. Dr. GUI can recommend a number of good ones. He really likes both Dale Rogerson's Inside COM (Microsoft Press, 1997) and Don Box's Essential COM (Addison-Wesley, 1998). Books like Adam Denning's ActiveX Controls Inside Out (Microsoft Press, 1996) and Professional Visual C++ 5 ActiveX/COM Control Programming by Sing Li and Panos Economopoulos (WROX Press, 1997) are good, too. And of course, you'll want Kraig Brockschmidt's Inside OLE, 2nd Edition (Microsoft Press, 1995) – the ultimate printed OLE reference. (MSDN is the ultimate reference, of course – not that the good doctor has an opinion.) And if you want a formal, nonpartisan explanation of component software, check out Clemens Szyperski's new book, Component Software: Beyond Object-Oriented Programming (Addison-Wesley, 1998).
"So what," you ask, "could Dr. GUI possibly add to all this?"
"Nothing," the good doctor would respond. These authors (and others) plus the documentation truly say it all. If you can find the time to read them, that is.
"So that's what you're up to!" you exclaim. "You're going to give us a gentle introduction to COM and ATL – just a few screenfuls each week!"
And Dr. GUI replies, "You're smart. This is going to be easier than I thought."
Components? Am I programming a stereo?
If you've used Visual Basic much, you're very familiar with using components to do your programming: you use both visual ActiveX controls (such as spin buttons) and nonvisual ActiveX components (such as database access objects). It's hard to find a significant Visual Basic program that doesn't make heavy use of premade reusable components. But although you reuse plenty of components, most folks don't yet write a whole lot of reusable components of their own.
If you're programming in C++, you likely have a different experience of reuse. C++ and object-oriented programming claim to make reuse easy, but what has your experience been? Have you been able to create a library of reusable objects? A few of you no doubt have, but most of us have not. And if we have such a library, do we routinely make good use of it? It's not just a lack of discipline that keeps us from reusing our code: the fact is that it's hard to reuse code (it never seems to do quite what we need) and it's even harder to write reusable code (it's very hard to be general enough yet useful enough).
On top of that, what C++ makes easy is not creation of reusable binary components; rather, C++ makes it relatively easy to reuse source code. Note that most major C++ libraries are shipped in source form, not compiled form. It's all too often necessary to look at that source in order to inherit correctly from an object – and it's all too easy (and often necessary) to rely on implementation details of the original library when you reuse it. As if that isn't bad enough, it's often tempting (or necessary) to modify the original source and do a private build of the library. (How many private builds of MFC are there? The world will never know . . .)
So let's reuse binary objects, not source code
So how can you reuse binary objects? Well, the answer that first comes to a Windows programmer's mind is simple: use dynamic-link libraries (DLLs). Using DLLs does work – Windows is itself, after all, primarily a set of DLLs. But there are some problems.
First, DLLs are not necessarily programming-language independent. Even for DLLs written in C, it's all too easy to change the calling convention (which parameters are pushed in which order?) such that the DLL is only usable from C programs. Granted, the calling convention used by Windows is pretty well established as the standard for Windows systems, but the good doctor has seen DLLs fail because of mismatched calling conventions.
Writing a C-style interface for your DLL has some major limitations. First off, it restricts you from doing object-oriented programming because the object-oriented features of C++ require name decoration of function names. There is no standard for name decoration; in some cases, different versions of the same compiler decorate names differently. Second, implementing polymorphism is difficult. You can work around these problems by creating wrapper classes for both sides, but doing so is painful. And Dr. GUI's not into pain. (Not too much, anyway.)
Even if you did resolve the name decoration problems so you could link successfully to the DLL, other problems arise when it comes time to update your objects.
First off, you're hosed (that's a medical term) if you add any virtual functions to your object when you update it. You might think you're okay if you add the new functions to the end, but you're not: you've just shifted the vtable entries for all objects that inherit from you. And since a virtual function call needs a fixed offset into the vtable in order to call the correct function, you can't make any changes to the vtable – at least not without recompiling every program that uses your object or any object derived from it. Clearly, recompiling the world every time you update your object is not an option.
Second, if you're using new in your client to allocate objects, you won't be able to change the size of the object (that is, add any data) without recompiling the world.
Lastly (and most importantly), updating DLLs is a nightmare because you're stuck between a rock and a hard place with two unappetizing options: either try to update the DLL "in place" by overwriting it or rename the new version. Updating the DLL in place is very bad: the chances that even if you keep the interface consistent you'll break some user of your DLL are very high. Dr. GUI doesn't need to tell you of all the problems the industry, including Microsoft, has run into because of this issue.
The alternative – using a new DLL name – will at least keep your working systems working. But there's a cost in disk space (perhaps not a big deal when typical hard disks are 3 gigabytes or so), and a second cost: increased memory usage. If your user is using both versions of the DLL, there will be two copies of very similar code in the user's working set. It's not unusual when you examine a user's memory usage to find two or three versions of the Visual Basic runtime or the Microsoft Foundation Class (MFC) DLL, for instance. Given that almost all Windows systems typically use more virtual memory than they have physical memory, increasing the working set size has serious performance implications in the form of increased virtual memory swapping to disk. (That's why, to paraphrase a counter-example to Brook's law, adding more memory to a slow system makes it faster.)
Ideally, you'd like to allow your user (or application) to be able to choose what version to use. This is VERY hard with statically linked DLLs, but very easy if you dynamically load your DLL.
To be fair to C++, we should note that it was never intended to solve this set of problems. C++ was intended to allow you to reuse code in programs that reside in one file, so all of the objects are compiled at the same time. C++ was not intended to provide a way to build reusable binary components that can be mixed and matched over versions and years. By the way, the creators of Java noticed these problems – these deficiencies were a major motivation for developing Oak, which later became Java.
So what about Java?
Java does solve some of these problems, but it also adds some of its own. The biggest problem is that Java components (JavaBeans, usually) are only intended to be used by programs written in Java. Now it's true that the Microsoft virtual machine (VM) allows you to use JavaBeans as COM objects. You can therefore use them from any language. And it's true that Sun has a Java/ActiveX bridge. But in general, unless you're running on Windows, Java is a single-language system: Java components can only be used in Java programs. And, for the most part, you have to rewrite your systems from scratch to use Java. (Yes, you can make native calls – but it's a big hassle to do using Java Native Interface (JNI) – and your programs will no longer be at all portable.) Dr. GUI finds this pretty unacceptable, so he's glad that the Microsoft virtual machine (VM) is more flexible – for Windows, at least. No language, not even C++, Visual Basic, or Java, is right for every programmer and every problem.
Java also makes you decide when you write your program whether the component you're using is local (on your machine) or remote (on another machine) – and the methods for using local and remote components are quite different.
Java has a couple of other issues that make it a less-than-ideal answer for all component needs. First, it has no really solid way to deal with versioning. (The package manager in the Microsoft VM helps a lot with this issue.) Second, Java will be to one degree or another slower than C++. Dr. GUI notes that recent "it's as fast as C++" benchmarks published in an online Java magazine omitted tests where Java would do poorly. Two examples that come to mind are string and array manipulation (Java has to bounds-check each access), and initial method calls (Java has to look up the method by signature in a table in the class for the first call, although subsequent calls, which the magazine did test, can be fast). Finally, Java's "one-class-at-a-time" loading scheme can be considerably slower than loading all the code at once (even if there's less code!) because it requires so many more file or HTTP transactions, both of which have a high overhead.
Even if you're using Java in a way that gives good performance, your performance will suffer when you use Java components from another language because of the translation layer that needs to be there to link the dissimilar languages and object models.
Where Java shines is in the possibility that you can use your compiled components on dissimilar machines without needing to recompile for each machine's processor and operating system. But this often doesn't "just work" – you'll need to test and debug on every platform you intend to support.
So what's the alternative?
As it turns out, it is possible to use C++ to build DLLs and other binary components that are reusable. Both Dale Rogerson's book, Inside COM, and Don Box's book, Essential COM, start with a C++ class they want to reuse and solve each of the problems I've listed above (and a few more) with some slick tricks. And both of them end up with, not surprisingly, COM. In other words, each of the solutions to the problem of binary reuse is an important feature of COM. (If you'd like to check this progression out now, check out Markus Horstmann's article, "From CPP to COM.")
While COM's "native language" is C++, it's relatively easy to use COM from C – the headers even support this. And, with a few language tweaks, it's possible to have two-way COM support from any language – Visual Basic, Java, Delphi, and so on. (By two-way COM support, I mean that it's possible both to use COM objects from that language, and to write COM objects in that language.) Implementing COM compatibility in your language run time isn't trivial, but the benefits are great: once you do, you open up a whole world of already written and debugged COM objects for your use. And there's a wide market for the COM components you write – the Giga Information Group estimates the current market at $400 million a year and expects it to be $3 billion in three years. (The COM-component market is growing faster than Microsoft!) Note that these market estimates are for third-party COM objects: they exclude COM components provided by Microsoft.
Another key feature of COM is that three types of objects are supported: in process (DLL), local (EXE in separate process on the same machine), and remote (DLL or EXE on a different machine via Distributed COM, or DCOM). You write code that uses COM components without worrying (or even knowing) what type of COM object you'll end up using, so you use the exact same code to hook up to an in-process, local, or remote object. How does COM hook you up to the right object? Well, it looks for the object's Class ID in the registry – and the registry entries tell COM which type or types of objects are available. COM does the rest, including starting processes and communicating over the network. (Note: there are performance differences between the different types of COM objects that you'll need to think about – but at least the code for connecting to and using the objects is exactly the same no matter what type of object you eventually use.)
COM doesn't solve all of the world's problems, however. For instance, it's still possible to break programs that use your component when you update a component. (Perhaps the fact that COM enforces a "black box" view of the component where it's not possible to find implementation details makes such breakage less common, but they still occur.) So you still have to choose between updating components in place and risking breakage, and using new Class IDs for new components. But COM does make it somewhat easier to write code that allows the user (or application) to choose what version it will use without recompilation.
Recall that COM components can be written in and used from most any language, and they can reside on any machine. That's nice. But what about cross-platform support?
Well, the cross-platform story is a good-news/bad-news story. The bad news is that there isn't very much COM on any platform besides Win32 right now. There are a couple of ports of COM to some non-Windows platforms, but not many. But that's not all the news.
The good news is that many more ports – to most common UNIX versions and to MVS – are coming, and soon. Further, Microsoft is doing some of the porting work itself. So it won't be long until COM and DCOM will be available on your favorite mainframes and UNIX boxes – availability for UNIX is scheduled to be announced in February. And think of how cool it'll be to have remote COM objects written in any language running on some fast mainframe that you can access from any language (Visual Basic, Java, Delphi, C++) on your machine. Check out the latest information on the Microsoft COM Web site.
So if you're developing for Windows, you'll certainly want to consider writing COM objects, no matter whether you develop in Visual Basic, Java, C++, Delphi, or some other COM-compatible language. The objects you write will be usable on the local machine or remotely without rebuilding your component or the component's clients, thanks to the magic of COM and DCOM. And if you need your solutions to run on platforms other than Windows, COM is looking better and better, so it's still certainly worth looking into and seriously considering.
Coming up next: Basic COM concepts you should know
Next week, we'll talk about the basics of COM: objects, interfaces, and modules. And we'll start to dig into the C++ code for a simple COM object, if we have time. (If not, we'll do it the week after next.)
Part 2: Basics of COM
In Part 1, the good doctor talked about why a language like C++ doesn't solve the problem of allowing you to build software out of binary components. The gist of that discussion was that C++ wasn't intended to solve this problem; rather, it was intended to make reuse of source code easy for single-executable programs. C++ meets that goal quite well. But we want to be able to mix and match components from different vendors without rebuilding parts (or all) of the system each time a component changes. We went into a lot of reasons why the C++ model doesn't work in this scenario.
So then what? Do you have to abandon C++? Nope – but you have to use it in a way that's a little different than what you're used to. And that's what we'll discuss next – how to use COM from C++.
Does that mean that you should stop reading if you're not a C++ programmer? No, because whatever COM-compatible language you're using (Visual Basic, Visual J++, Delphi, and others) will be doing the things we discuss under the hood (or is that in the operating room?). So if you read on, you'll gain valuable insights as to how those ActiveX controls and COM components work.
Okay, so what is COM?
The Component Object Model (COM) is a way for software components to communicate with each other. It's a binary and network standard that allows any two components to communicate regardless of what machine they're running on (as long as the machines are connected), what operating systems the machines are running (as long as it supports COM), and what language the components are written in. COM further provides location transparency: it doesn't matter to you when you write your components whether the other components are in-process DLLs, local EXEs, or components located on some other machine. (There are performance implications, of course, but you don't have to rewrite a thing to change the other components' locations – that's key.)
Objects
COM is based on objects – but the objects aren't quite the objects you're used to in C++ or Visual Basic. (By the way, an object and a component are pretty much the same thing. Dr. GUI will tend to say "component" when he's talking about application architecture and "object" when he's talking about implementations.)
First off, COM objects are well encapsulated. You cannot gain access to the internal implementation of the object; you have no way of knowing what data structures the object might be using. In fact, the objects are so well encapsulated that COM objects are usually just drawn as boxes. Figure 1 is a drawing of an utterly encapsulated object. Note how the implementation details are hidden from you.

Figure 1. An utterly encapsulated, non-COM object.
That's all well and good for encapsulation, but what about communication? As it stands, we have no way to communicate with the component in that box. Clearly, this won't do.
Interfaces: Communications with an object
That's where interfaces come in. The only way to access a COM object is through an interface. We can draw an interface called IFoo on an object like the one shown in Figure 2.
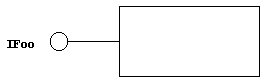
Figure 2. Object with interface – still not COM.
The thing that looks like a lollipop sticking out of the side of our object is the interface – in this case, the IFoo interface. This interface is the only way to communicate with this object. The good doctor finds it more useful to think of an interface as being like a plug-in connector than a lollipop. It's how you plug into the functionality of the object. Think of it as being like the antenna input to your VCR or TV.
An interface is two things. First, it's a set of functions that you can call to get the object to do something. In C++, interfaces are represented as abstract base classes. For instance, the definition of IFoo might be:
class IFoo {
virtual void Func1(void) = 0;
virtual void Func2(int nCount) = 0;
};
We'll ignore the return types and inheritance for now . . . but do note that there can be more than one function in the interface and that all of the functions are pure virtual functions: they do not have implementations in class IFoo. We're not defining behavior here – we're only defining what functions are in the interface. (A real object has to have implementation, of course – more on that later.)
Second – and more importantly – an interface is a contract between the component and its clients. In other words, an interface not only defines what functions are available, it also defines what the object does when the functions are called. This semantic definition is not in terms of the specific implementation of the object, so there's no way to represent it in C++ code (although we can provide a specific implementation in C++). Rather, the definition is in terms of the object's behavior, so that revisions to the object and/or new objects that also implement the interface (contract) are possible. In fact, the object is free to implement the contract in any way it chooses (as long as it honors the contract). In other words, the contract has to be (gasp!) documented outside of the source code. This is especially important since clients won't get (and don't need) the source code.
This notion of a specific contract is crucial to COM and to component software in general. Without "ironclad" contracts, it would be impossible to interchange components.
Interface contracts, like diamonds, are forever
In COM, once you "publish" an interface contract by shipping a component, the contract is immutable – it cannot be changed in any way. You can not add. You can not delete. You can not modify. Why? Because other components are depending on the contract. If you change the contract, you'll break that software. You can improve your internal implementation as long as you still honor the contract.
What if you've forgotten something? What if requirements change? How does the world improve?
The answer's easy: you write a new contract. The standard OLE interface list has many of these: IClassFactory and IClassFactory2, IViewObject and IViewObject2, and so on. And you can, of course, provide an IFoo2. (I'm sure you've noticed by now that interface names, by convention, begin with an uppercase I.)
So if I write a new contract, how does software that only knows about the old contract still use my components? Won't that mess old components up?
COM objects can support multiple interfaces – they can implement multiple contracts
The answer to that is also no – and the reason is simple: in COM, an object can support multiple interfaces. In fact, all useful COM objects support at least two interfaces. (At least the standard IUnknown interface – more on this later – and an interface that does what you want the object to do.) Visual ActiveX controls support about a dozen interfaces, most of them standard interfaces. In order for a component to support an interface, it has to implement each and every method in that interface, so this is a very substantial task. That's why tools like the Active Template Library (ATL) and so forth are popular: they provide implementation for all of the interfaces.
So in order to support the new IFoo2 functionality, we add our IFoo2 to this object as well.
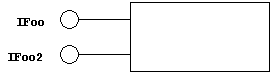
Figure 3. Version 2.0, which supports both IFoo and IFoo2 – but still is not a COM object.
If you're still thinking of plugs, think of IFoo as the antenna input to your TV and IFoo2 as the composite video input. Note that you can't plug the antenna cable into the composite video input – or vice versa. In other words, each interface is logically unique.
On the other hand, these interfaces do have something in common. Do I have to rewrite the whole implementation just to add a new interface that's almost exactly the same as the old one? No, because COM supports inheritance of interfaces. As long as we don't change the functions already in IFoo, we can define IFoo2 as follows:
class IFoo2 : public IFoo {
// Inherited Func1, Func2
virtual void Func2Ex(double nCount) = 0;
};
Interface review
So let's review what we've seen. First off, COM is a binary standard for software object interaction. Since it's a binary standard, objects don't – and can't – know of the implementation details of the objects they use. Objects, therefore, are black boxes.
We manipulate these black box objects only through the interfaces the objects expose. Finally, a given object can expose as many interfaces as it chooses.
Simple, right?
Well, we've ignored a lot of details. How do those objects get created? How do you gain access to an interface? How do you call an interface's methods? And where's the implementation of these objects, anyway? And when will that pesky object finally be destroyed?
These are great questions – but unfortunately Dr. GUI's almost late for surgery, so we'll have to postpone the answers until Part 3. But the good doctor will deal with one issue now: How are interface methods called?
Calling interface methods
You may have seen this coming already, but this ends up being very simple: COM method calls are merely C++ virtual function calls. We will somehow (more on this in Part 3) get a pointer to an object that implements an interface, then we'll just call the methods of the interface.
First, let's assume that we have a C++ class called CFoo that implements the IFoo interface. Notice that we inherit from IFoo to insure that we implement the proper interface in the proper order.
class CFoo : public IFoo {
void Func1() { /* ... */ }
void Func2(int nCount) { /* ... */ }
};
The pointer we use will be called an interface pointer. Assuming we can get one, our code might look something like this:
#include <IFOO.H // Don't need CFoo, just the interface
void DoFoo() {
IFoo *pFoo = Fn_That_Gets_An_IFoo_Pointer_To_A_CFoo_Object();
// Call the methods.
pFoo -> Func1();
pFoo -> Func2(5);
};
It really is that simple.
But what really goes on underneath? Well, as it turns out, the COM binary standard applies to method calls, too – so COM defines what happens in order to call the function. Specifically, the same thing happens that happens for a virtual function call:
- pFoo is dereferenced to find the vtable pointer in the
object.
- The vtable pointer is dereferenced and indexed to find
the address of the function to be called.
- The function is called.
See Figure 4 for the numbered steps:
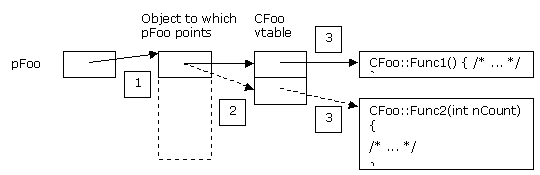
Figure 4. C++ virtual function calls through interface pointer
Remember that in C++ every time you have virtual functions you'll have a vtable that points to those functions – and that the calls are always done by indexing into the vtable.
"Aha!" you say. "I knew it. COM is really tied to C++! It's not a binary standard at all!"
To which Dr. GUI replies, "Nonsense." After all, you can implement this call in any language that supports arrays of function pointers. It's easy to do it in C, for instance – a call to Func2 through the pointer p would look like:
(*((*p)+1))(p, 5); // passing 5 to the 2nd function in the array
Note that we have to pass p as the first parameter – this simulates the C++ this pointer. (*p) is the first indirection (step 1), *((*p) + 1) is the index into the vtable (step 2), and then we call the function with p and 5 (step 3). It's easy, but it's ugly – Dr. GUI showed it so you'd know you could do it (and to make you appreciate C++). In x86 assembly language, it might look something like this:
MOV EAX, [pFoo] ; step 1
MOV EAX, [EAX + 4] ; step 2, indexed to 2nd pointer
CALL [EAX] ; step 3
Dr. GUI is aware that the second and third instructions could be combined into CALL [EAX + 4] if you didn't need to keep the address of the function in EAX.
Why did the good doctor show all this detail? Well, if you can do it in assembly or C, you can do it in any language! Other languages (Visual Basic, Visual J++, Delphi) build the support for doing these calls into their run times or virtual machines – often by using assembly or C code similar to the above.
The point is that any COM method call must use the data structures shown in order to do a call, regardless of what the original language is – or regardless of where the COM object is. We'll discuss how COM achieves location transparency in a future column.
Where we've been; where we're going
Okay . . . so we've discussed interfaces, objects, and how interface methods are called.
An object is the basic unit of COM – it's the thing that COM creates. An object implements some set of interfaces. An interface is a set of methods and a contract for what those methods do. Interface methods are called in the same manner a C++ virtual function is called.
In Part 3, we'll talk about how to create these objects, how to get interface pointers, and how objects are destroyed.
Part 3: Getting Objects and Interfaces
In Part 2, we discussed two really basic concepts in COM: objects and interfaces. We also showed how an object could implement more than one interface. Finally, we discussed the nitty-gritty of how COM method calls are made – and noticed that they're the same as C++ virtual function calls. (But we also noted that you can do them in any language that supports – or can call assembly language to support – pointers to arrays of function pointers.)
More on COM: Creation and Destruction of Objects; Getting Interface Pointers
But you might have found the discussion somewhat unsatisfying: we never talked about how to create an object, nor did we discuss how to get an interface pointer so we could call methods on the object's interface. And we never talked about how to get rid of objects you no longer need, or how to switch interfaces.
The good doctor will shed some light on these topics in this week's discussion. But first, we need to take care of a little housekeeping. You know how sometimes you go to explain something and you suddenly remember that you forgot a few important things? That's what's happened here – the good doctor forgot that in order to create objects, you've gotta be able to have a way to refer to them – and a way to clearly define your interfaces. So we'll talk about the forgotten pieces, then cover the real fun stuff. (And that's why this column is long – and late.)
Identifiers in COM
If you're thinking ahead, you've noticed that we're going to need some identifiers for various entities in the COM world. First, we're going to need an identifier for the object type (or class). Second, we'll need an identifier for each interface. But what should we use for an identifier? A 32-bit int? A 64-bit int? Well, perhaps we could. But there's a problem: the identifiers will have to be unique across all machines, since there's no way of knowing what machines you'll want to install a component on. Your objects and interfaces will need the same identifier on all machines so that any client can use your component. Further, no other object or interface may use that identifier, no matter where it came from. In other words, these identifiers must be globally unique.
Fortunately, algorithms and data formats exist for creating such identifiers. By using your machine's unique network card ID, the current time, and other data, these identifiers, called GUIDs (globally unique identifiers) are created by a program called GUIDGEN.EXE. GUIDs are stored in 16-byte (128 bit) structures, giving 2128 possible GUIDs. But don't worry about running out of GUIDs: although the good doctor was unable to find the exact number of atoms in the universe, even after searching the Web, he believes it's significantly less than 2128 So there's no shortage of GUIDs and no need for GUID conservation, despite the in-jokes of COM practitioners.
In C++, there are data types defined by COM header files for GUID, CLSID (class identifier GUID), and IID (interface identifier GUID). Since these 16-byte structures are kind of large to be passing around by value, you'll usually use REFCLSID and REFIID as the data types of parameters when passing GUIDs. You will have to create a CLSID for each object type you write and an IID for each custom interface you create.
Standard interfaces
COM defines a large set of standard interfaces and their associated IIDs. For instance, the mother of all interfaces, IUnknown, has an IID of "00000000-0000-0000-c000-000000000046" (the hyphens are part of the standard way of writing GUIDs). This IID is defined by COM and you need never refer to it directly; instead, use the symbol IID_IUnknown, which is defined for you in the headers.
The IUnknown interface has three functions:
HRESULT QueryInterface(REFIID riid, void **ppvObject);
ULONG AddRef();
ULONG Release();
We'll discuss exactly what these functions do later.
Much of your COM programming will be done using standard interfaces – a lot of it will be providing implementations for standard interfaces so that other COM clients and objects can use your object.
By the way, there are some macros used in COM to describe the return types and calling conventions of functions. Almost all COM methods return an HRESULT, so the macro STDMETHODIMP assumes that. The macro STDMETHODIMP_() takes a parameter – the return type of the method. (You only use the STDMETHOD macro when you're defining an interface with pure virtual functions – and the IDL compiler writes that code for you – more on that later.)
Using these macros, the declarations above would look like this:
STDMETHODIMP QueryInterface(REFIID riid, void **ppvObject);
STDMETHODIMP_(ULONG) AddRef();
STDMETHODIMP_(ULONG) Release();
We'll use these macros from now on out. Doing so makes it easy to port your code to different COM platforms (such as Macintosh and Solaris).
Custom interfaces
Custom interfaces are interfaces you create. You'll create your own IID for these interfaces, and define your own list of functions. Our IFoo interface is a custom interface. I've defined an IID called IID_IFoo (which has the value "13C0205C-A753-11d1-A52D-0000F8751BA7") by running the GUID generator on my machine.
Recall that the class declaration was originally:
class IFoo {
virtual void Func1(void) = 0;
virtual void Func2(int nCount) = 0;
};
We'll modify this to be COM-compliant by changing it around a bit:
interface IFoo : IUnknown {
virtual HRESULT STDMETHODCALLTYPE Func1(void) = 0;
virtual HRESULT STDMETHODCALLTYPE Func2(int nCount) = 0;
};
Using the macros as described above, this becomes:
interface IFoo : IUnknown {
STDMETHOD Func1(void) PURE;
STDMETHOD Func2(int nCount) PURE;
};
The word "interface" is not a keyword in C++, rather it is #defined in the appropriate COM header as "struct". (Recall that in C++ classes and structs are the same except that structs use public inheritance and access by default rather than private.) STDMETHOD uisesSTDMETHODCALLTYPE, which is defined as __stdcall, indicating that the compiler should generate the standard function calling sequence for these functions. Remember, we use these macros because the definitions of them will change as we port our code to different platforms.
All COM functions (with almost no exceptions) return an HRESULT error code. This HRESULT is a 32-bit number that uses the sign bit to represent success or failure and fields in the remaining 31 bits to indicate the "facility" and the error code (which is specific to the facility), and some reserved bits. Normally you'll want to return the success code S_OK, but you can return an error code – either a standard one or one you make up – if you encounter a problem in your method.
Finally, note that I'm deriving IFoo from the standard COM interface IUnknown. That means that any class that implements IFoo will also need to implement the three functions AddRef, Release, and QueryInterface. Also, the IFoo vtable will have pointers to these three functions before the pointers to Func1 and Func2. That's a total of five functions in the vtable, and five functions to implement. All COM interfaces are derived from IUnknown, so all COM interfaces contain these three functions in addition to any other functions.
What's that thing in the MIDL?
You won't actually write the declaration above yourself – it'll be generated for you by the MIDL compiler. Why? Well, as it turns out, C++ can't express everything that needs to be expressed in an interface. Recall that COM objects can be DLLs to be used in-process, meaning in the same address space. So if you pass a pointer to some data to an in-process server, the server can dereference the pointer directly.
But also recall that your COM object can be a local (out-of-process) server in separate EXE address spaces, or even accessed remotely. Any time you need to pass a pointer to a COM method in such an object, you're got a problem: the pointer is meaningless in any other address space. What's meaningful is the data to which the pointer points. This data has to be copied into the other address space – and perhaps back. This process of copying the right data is called marshalling. Thankfully, COM does the marshalling for you in most cases. But in order for it to do so, you need to tell it more than just the type the pointer points to – you need to tell COM how the pointer is used. For instance, does the pointer point to an array? A string? Is the parameter an input parameter only? An output parameter? Both? You can see that there's no way to express this in C++.
So we'll need another language, called IDL (Interface Definition Language) to define the interface. IDL looks a lot like C++, but it has "attributes" in square brackets added in to the C++-like code. MIDL.EXE compiles the IDL file you (or Visual Studio) write to produce a variety of outputs. For now, the only output we care about is the header file for our interface, which we'll include in our code.
In our example, it doesn't make any difference since we're only passing by value, so the IDL code looks very similar – the main difference is that the word "virtual" is missing. But if we created a new interface IFoo2 which adds a method Func3(int *) to the other two methods, the IDL would look something like this:
[ uuid(E312522F-A7B7-11D1-A52E-0000F8751BA7) ]
interface IFoo2 : IUnknown
{
HRESULT Func1();
HRESULT Func2(int in_only);
HRESULT Func3([in, out] int *inout);
};
Note a few things. First, there are various attributes in the IDL, enclosed in square brackets. The attributes always apply to the thing immediately after, so the UUID attribute above applies to the interface – it's the IID for the interface. (UUID, or universally unique identifier, is a synonym for GUID.) The [in, out] attribute applies to the pointer and tells COM that it will have to marshal a single int both in and out when it calls Func3 (if marshalling is required). If the int pointer referred to an array, it would have an additional attribute (size_is with a parameter). There is IDL code to define the object as well. For instance, the code fragment to define our object might look like this:
[ uuid(E312522E-A7B7-11D1-A52E-0000F8751BA7) ]
coclass Foo
{
[default] interface IFoo;
};
This is how the CLSID is associated with the class – and how the set of interfaces the class implements is defined. Note that although this looks a lot like C++ with a couple of additional attributes, it doesn't correspond exactly to C++ code like the interface definition does.
Creation of objects
Once our CLSID is associated with an object type (more on this later), we can create an object. As it turns out, this is very simple – just one function call:
IFoo *pFoo = NULL;
HRESULT hr = CoCreateInstance(CLSID_Foo, NULL, CLSCTX_ALL,
IID_IFoo, (void **)&pFoo);
If CoCreateInstance succeeds, it creates an instance of the object identified by the CLSID GUID, CLSID_Foo. Note that there's no such thing as a "pointer to the object"; instead, we always refer to the object through an interface pointer. So we have to specify which interface we want (IID_IFoo) and pass a pointer to a place for CoCreateInstance to store the interface pointer.
The two parameters we've not discussed yet are not important at the moment.
Once we make the call, we check to make sure that the call succeeded and go ahead and use the object:
if (SUCCEEDED(hr)) {
pFoo->Func1(); // Call methods.
pFoo->Func2(5);
pFoo->Release(); // MUST release interface when done.
}
else // Creation failed...
CoCreateInstance returns an HRESULT to indicate whether it succeeded or not. Always use the SUCCEEDED macro to check the result since nonnegative values mean success. In fact the most common success code, S_OK, is zero – so a check like "if (hr) // Success" won't work at all. Once the object has been created successfully, you can use the interface pointer to call the methods of the interface, as shown above.
It is vitally important that you release the interface pointer when you're done with it by calling Release. Note that since all interfaces are derived from IUnknown, all interfaces support Release. The COM object is responsible for freeing itself when you tell it you're done with it, but it relies on you to tell it when you're done. If we'd forgotten to call Release, the object would be leaked (and locked in memory at least until our application closed – and perhaps until the system is rebooted). Messing up object lifetime is a very common COM programming problem – and it's often difficult to find. So be careful, starting now. Note that we only release the interface if we were actually able to create it.
Figure 5 is a diagram of our newly created object. By convention, IUnknown is not labeled; it's always drawn attached to the upper right hand corner of the object. All of the other interfaces are drawn on the left.
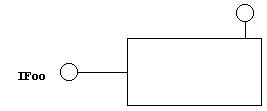
Figure 5. Our first simple COM object, with unlabeled IUnknown.
Now that we have IUnknown implemented, we really have a COM object. (If only it was as simple as drawing a connector!)
If we'd added an IFoo2 interface to the object, we'd have a total of three interfaces, drawn as in Figure 6.
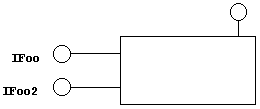
Figure 6. Theoretical version 2.0, which supports both IFoo and IFoo2.
GUIDs and the registry
So how did COM find the object's code in order to create it? Simple: it looked in the registry. When a COM component is installed, it has to have entries made in the registry. For our Foo class, the entry might look something like this:
HKEY_CLASSES_ROOT
CLSID
{E312522E-A7B7-11D1-A52E-0000F8751BA7}="Foo Class"
InprocServer32="D:\\ATL Examples\Foo\\Debug\\Foo.dll"
Most objects will have some additional entries, but we can ignore these for now.
At HKEY_CLASSES_ROOT\CLSID, there's an entry for the CLSID of our class. That is how CoCreateInstance looks up the DLL name for the component. When you provide CoCreateInstance with the CLSID, finds the DLL name, loads the DLL, and creates the component (more on this later).
The registry entries would look somewhat different if the server was out-of-process or remote, but the main point is that the information would be there so that COM could start the server and create the object.
If you know the name (ProgID) of the object but not its CLSID, you can look up the CLSID in the registry. For our object, there's an entry at:
HKEY_CLASSES_ROOT
Foo.Foo="Foo Class"
CURVER="Foo.Foo.1"
CLSID="{E312522E-A7B7-11D1-A52E-0000F8751BA7}"
Foo.Foo.1="Foo Class"
CLSID="{E312522E-A7B7-11D1-A52E-0000F8751BA7}"
"Foo.Foo" is the version-independent ProgID, and Foo.Foo.1 is the ProgID. If you create a Foo object from Visual Basic, the CLSID is looked up using one of these ProgIDs. (Note that the ATL wizards don't create the registry entries quite correctly in current versions: they leave out the first of the two CLSID keys shown above. Don't forget to make a copy of the CLSID for the version-independent ProgID.)
Modules, component classes, and interfaces
Note that it's possible – in fact common – for one module (DLL or EXE) to implement more than one COM component class. When this happens, there will be more than one CLSID entry that refers to the same module.
So now we can define the relationship between modules, classes, and interfaces. A module (the basic unit that you build and install) can implement one or more components. Each component will have its own CLSID and entry in the registry that points to the module's file name. And each component implements at least two interfaces: IUnknown, and an interface that exposes the component's functionality. Figure 7 shows this.
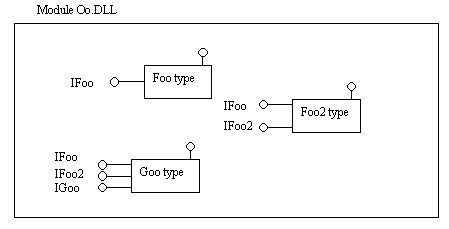
Figure 7. Module Oo.DLL contains implementations for three objects: Foo, Goo, and Hoo. Each object implements IUnknown and one or more additional interfaces.
Getting to the other interfaces with QueryInterface
Let's say that we have a new and improved Foo2 object that implements two custom interfaces: IFoo and IFoo2. We already know how to create such an object using CoCreateInstance and how to get a pointer to one of its three (don't forget IUnknown) interfaces.
Once we've got that interface pointer, how do we get an interface pointer to one of the object's other interfaces? We can't call CoCreateInstance again – that would create a new object. We don't want that – we only want a different interface on the existing object.
That's the problem that IUnknown::QueryInterface solves. Remember, because all interfaces inherit from IUnknown, all interfaces implement QueryInterface. So we'll just use the first interface pointer to call QueryInterface to get the second interface pointer:
IFoo *pFoo = NULL;
HRESULT hr = CoCreateInstance(CLSID_Foo2, NULL, CLSCTX_ALL,
IID_IFoo, (void **)&pFoo);
if (SUCCEEDED(hr)) {
pFoo->Func1(); // call IFoo::Func1
IFoo2 *pFoo2 = NULL;
hr = pFoo->QueryInterface(IID_IFoo2, (void **)&pFoo2);
if (SUCCEEDED(hr)) {
int inoutval = 5;
pFoo2->Func3(&inoutval); // IFoo2::Func3
pFoo2->Release();
}
pFoo->Release();
}
We pass QueryInterface the IID of the interface we want and a pointer to the place for QueryInterface to store the new interface pointer. Once QueryInterface returns successfully, we can use the interface pointer to call that interface's function.
Note well that we must release both interface pointers when we're done with them. Failure to release either of them will leak the object. Since we never refer to the object except through interface pointers, we have to release each and every interface pointer we get in order for the object as a whole to be released.
IUnknown's other functions
IUnknown has two other functions, AddRef and Release. We've seen already that you use Release to tell an object that you're done with an interface pointer. So when do you use AddRef?
Reference counts and when an object can be freed
Most COM objects keep a reference count – in other words, they're required to keep track of how many interface pointers to the object are in use. When the reference counts on all of the object's interfaces goes to zero, it can be freed. We don't explicitly free the object; we just release all of the object's interface pointers and the object frees itself at the appropriate time.
AddRef increments the reference count, and Release decrements it. So if we didn't call AddRef, why did we have to call Release?
Whenever QueryInterface hands out a new pointer to an object, it's responsibility of QueryInterface to call AddRef before returning the pointer. That's why we didn't have to call AddRef for the pointers we got: QueryInterface did it for us. (Note that CoCreateInstance calls QueryInterface – which calls AddRef – so this is true even for our first interface pointer to an object.)
Note that you're required to call Release on the same interface pointer on which you called AddRef. Objects can, if they want, keep track of references on an interface-by-interface basis. The code above carefully did this, correctly pairing implicit AddRef calls with the appropriate Release calls – one Release call for each interface pointer.
You need to call AddRef if you're making a copy of an interface pointer so that the reference count for the interface is accurate. When you need to do this or not is a bit complex, but it's well covered by various COM references. Check them out for the details.
Various smart pointer classes can make dealing with the great IUnknown much easier (in fact, automatic). There are several such classes in ATL and Visual C++ 5.0. And if you're using another language such as Visual Basic or Java, the language's implementation of COM deals with the IUnknown methods correctly for you.
Where we've been; where we're going
So we've talked about how to create objects and destroy them (we don't – we just release all of our interface pointers to them), and how to call interface methods and switch interfaces. Along the way, we also introduced the concepts of various GUIDs used to identify the objects and interfaces and the registry entries needed so that COM can figure out how to create your object.
In Part 4, we'll talk more specifically about how in-process objects are created, and ways to make that creation more efficient. If there's time, we'll also talk about the guts of implementing an object, including the code you need for creating an object and IUnknown.
Part 4: The Class Object and Class Factory
In Part 3, we talked about how to create and destroy objects (we don't destroy them – we just release all interface pointers to them) and how to call interface methods and switch interfaces. Along the way, we also introduced the concepts of the various GUIDs used to identify the objects and interfaces and the registry entries needed so that COM can figure out how to create your object.
This time, we'll talk more specifically about how in-process objects are created, and ways of making that creation more efficient. We'll also talk about the class object (also known as class factory) and how to implement one. There's not time this week to talk about implementing your actual object, but that'll be at the top of the agenda next week.
What happens when you call CoCreateInstance?
We've talked already about how, when you call CoCreateInstance, COM searches the registry to find the CLSID so it can find the DLL (or EXE) that implements the object. But we didn't explain the details of how that happens. CoCreateInstance encapsulates the following functionality:
IClassFactory *pCF;
CoGetClassObject(rclsid, dwClsContext, NULL,
IID_IClassFactory, (void **)&pCF);
hresult = pCF->CreateInstance(pUnkOuter, riid, ppvObj)
pCF->Release();
As we can see, there are three steps. The first step is to get a class object via its IID_IClassFactory interface. Next, we call IClassFactory::CreateInstance on this class object. (The parameters for this call are passed in from the CoCreateInstance call.) The parameter pUnkOuter is used for a reuse method called aggregation, which we'll talk about later. Assume that it's NULL for now. We now have a pointer to an instance of our object in *ppvObj. Finally, we release the class object.
So what is this class object? Why do we have to bother with it?
The Class Object
The class object is a special COM object whose main purpose is to implement the IClassFactory interface. (You'll often hear this object referred to as a "class factory" or even "class factory object," but it's more accurate to refer to it as the class object.)
If you've used Java extensively, you can think of the COM class object as being roughly like a Java object of class "Class." And you'll note that Java's Class.newInstance is analogous to IClassFactory::CreateInstance just as COM's CoGetClassObject is analogous to the Class.forName static method.
This object is special because it's not created by calling CoCreateInstance or IClassFactory::CreateInstance, as are most COM objects. Rather, it's always created by calling CoGetClassObject. We'll see other examples of special COM objects at the end of this article. (As it turns out, CoGetClassObject doesn't always create a class object. If COM has a class object for the right class available, it can just return an interface pointer to it.)
After the call to CoGetClassObject, note that the code doesn't have to worry about what kind of object it's creating – it doesn't matter whether it's an in-process or local server, for instance. The class object handles all those differences. CoGetClassObject, however, does need to do the work of digging through the registry (and list of existing registered class objects) in order to figure out how to create or find a class object for the CLSID requested.
The class object is a great example of the power of polymorphism. We call a COM API in order to get the object. But once we've got it, we can determine that it supports the standard interface we need (IClassFactory) and we can then call the methods of that interface – in this case, IClassFactory::CreateInstance. Note that we have no idea how the class object's CreateInstance works. All we know is that if it succeeds, it will return an interface pointer that refers to the object. We don't have to and don't want to know anything else (that's encapsulation) and we get the right behavior for the particular class object by making the exact same function call (that's polymorphism) – it's the identity of the class object that determines the exact behavior.
Each class object instance is associated with a particular CLSID – note that IClassFactory::CreateInstance does not have a CLSID as one of its parameters. Rather, the class object knows what CLSID it is to create. That means that you'll need at least one class object for each separate CLSID you want to be able to create.
In addition to IClassFactory, the class object can implement whatever interfaces it likes. For instance, you could define an interface that allows you to set defaults for object instances created from a particular class object. But note that you're not guaranteed that there is only one class object for a given CLSID, so if you call CoGetClassObject more than once, you may well get interface pointers to different class objects. (Since you control the creation of the class object, you can define this in your implementations.)
Why there's a class object
As we discussed, the most important reason for COM to require implementation of a class object is so that COM can have a standard polymorphic way of creating objects of any type without requiring the client to know the exact details of creation. The class object encapsulates that knowledge, so the client doesn't have to. This implies that the class object and the "real" object have a very close relationship – and often lot of knowledge of each other.
But why not a simpler scheme? For instance, you could imagine a function in your COM DLL called, say, DLLCreateInstance that would accept a CLSID and create a new instance. A function such as this is certainly simpler than a COM object and IClassFactory.
But it wouldn't work for EXEs. You don't just export functions from EXEs. And it certainly wouldn't work well for remote objects. So when we make the class object a COM object, COM takes care of all of the in-process and out-of-process issues for us. That's a good deal.
Since the class object is a COM object that knows how to "do the right thing" to create an instance of the target object, note that once the class object is created, COM is out of the picture in terms of creation of instances. So for the first object of a particular type that's created, COM has to do a lot of work. First, it has to look up the CLSID in the list of registered class objects (or in the registry if the class object doesn't exist). If the class object needs to be created, COM creates it, perhaps including loading a DLL or starting an EXE. Finally, COM calls IClassFactory::CreateInstance on the correct class object to create your instance. Phew!
But if you keep the class object around, you can skip most of the work for subsequent instances: just call IClassFactory::CreateInstance yourself to make additional objects. This can be almost as fast as calling operator new directly – and far faster than having COM create objects.
Important If you keep a class object around, you must call IClassFactory::LockServer to tell COM to keep the server in memory. The reference to the class object will not keep the server in memory automatically. This behavior is an exception to the normal COM behavior. If you fail to lock the server, you may cause a protection violation if you try to access the class object after the server's been unloaded. Don't forget to unlock the server when you're done with the class object.
Finally, the class object can support additional ways to create objects, such as the IClassFactory2 interface that's used instead of IClassFactory to create licensed controls. Licensed controls are controls that require the user to have the correct license ID before the control can be created.
Another way to create objects and when to use it
If you're creating only one instance of an object and if you can use IClassFactory to create the object, you may as well use CoCreateInstance (or CoCreateInstanceEx, which can create remote objects). But if you're creating more than one instance of an object, or if you need to use an interface besides IClassFactory to create the object, you'll need to get (and probably hold) a class object.
Getting the class object is easy – just do as CoCreateInstance does: call CoGetClassObject. Once you have the interface pointer to the class object, call IClassFactory::LockServer(TRUE) to lock the server in memory. Then you can hold on to the interface pointer to the class object and call IClassFactory::CreateInstance whenever you need a new instance. Finally, when you're done creating objects, release the server by calling IClassFactory::LockServer(FALSE) and release the interface pointer by calling Release on it. Remember that releasing the interface has to be the last thing you do to the interface.
Implementing the Class Object
So what does this class object look like? Well, it's a simple COM object. That means that it implements at least one interface: IUnknown. Almost all class objects also implement IClassFactory so they can create instances.
We might have a class object declared like this:
class CMyClassObject : public IClassFactory
{
protected:
ULONG m_cRef;
public:
CMyClassObject() : m_cRef(0) { };
//IUnknown members
STDMETHODIMP QueryInterface(REFIID, void **);
STDMETHODIMP_(ULONG) AddRef(void);
STDMETHODIMP_(ULONG) Release(void);
//IClassFactory members
STDMETHODIMP CreateInstance(IUnknown *, REFIID iid, void **ppv);
STDMETHODIMP LockServer(BOOL);
};
Of course, this class contains declarations for each of the functions in IclassFactory::CreateInstance and LockServer. Plus (surprise!), there are the IUnknown functions. (Remember that IClassFactory is derived from IUnknown, as are all COM interfaces.) Note that we have a member that holds the reference count for this object and that we've initialized it to zero in the constructor. Note also that we're using the official COM macros for declaring method impmentations.
How this class object is created
There are a variety of ways to create a class object, none of which involve CoCreateInstance. Since we really only need one instance of this object and since it's a small object with no constructor, I decided to just declare a global object in my code:
CMyClassObject g_cfMyClassObject;
That means that this object will always exist when the DLL is loaded.
In order to implement IClassFactory::LockServer, we'll also need a global count of all of the nonclass object instances and the number of times LockServer was called:
LONG g_cObjectsAndLocks = 0;
How CoGetClassObject gets the class object
For in-process DLL servers, this is simple: COM calls a function called DllGetClassObject in your DLL. You must export this function if your DLL contains COM-creatable COM objects. DllGetClassObject has the following prototype:
STDAPI DllGetClassObject(const CLSID &rclsid, const IID &riid,
void ** ppv);
COM passes in a CLSID and an IID; DllGetClassObject returns a pointer to the requested interface in *ppv. If the class object can't be created or the requested interface doesn't exist, an error is returned in the HRESULT return value (note that STDAPI is #defined to return an HRESULT).
For EXE servers, the process is different: You register a class object for each class COM can create by calling CoRegisterClassObject for each class object. This puts the class objects in the list of registered class objects. When the EXE process ends, it calls CoRevokeClassObject once per class object to remove the objects from the registered list. If you need more details on this, check the COM docs or various COM books – I'd like to focus on in-process (DLL) servers here.
Note, then, that how COM actually gets the class object when you call CoGetClassObject depends on whether the object is implemented by a DLL or an EXE. If a DLL, it loads the DLL (if not already loaded) and calls DllGetClassObject. For an EXE, it loads the EXE (if not already loaded) and waits until the EXE registers the class object it's looking for or until a timeout occurs.
Our DllGetClassObject might look like this:
STDAPI DllGetClassObject(REFCLSID clsid, REFIID iid, void **ppv) {
if (clsid != CLSID_MyObject) // Right CLSID?
return CLASS_E_CLASSNOTAVAILABLE;
// Get the interface from the global object.
HRESULT hr = g_cfMyClassObject.QueryInterface(iid, ppv);
if (FAILED(hr))
*ppv = NULL;
return hr;
}
We must check to see that the CLSID requested is the one we support. If not, we return E_FAIL. Next, we QueryInterface for the interface requested. If this fails, we set the output pointer to NULL and return E_NOINTERFACE. If it succeeds, we return S_OK and the interface pointer.
Implementing the Methods of the Class Object
IUnknown::AddRef and IUnknown::Release
Our class object is global. It always exists and it can't be destroyed (at least not until the DLL is unloaded). Since we'll never delete this object and since references to class objects don't keep a server loaded, we almost don't need to implement reference counting. However, reference counting can be handy for debugging, so we'll implement it in this object anyway.
AddRef and Release are responsible for maintaining the reference count on the object. Note that we have an instance variable m_cRef that's been initialized to zero. AddRef and Release will just increment and decrement the reference counter and return the new value of the reference counter.
If the object was dynamically created, it would be the responsibility of Release to delete the object when the reference count went to zero. Since our object is globally allocated, we can't do that.
STDMETHODIMP_(ULONG) CMyClassObject::AddRef() {
return InterlockedIncrement(&m_cRef);
}
STDMETHODIMP_(ULONG) CMyClassObject::Release() {
return InterlockedDecrement(&m_cRef);
}
I used the thread-safe increment and decrement functions rather than just using ++m_cRef and --m_cRef to get into the habit of thinking about multithreaded operation.
If you wanted to make AddRef and Release real simple, you could simply have them return a nonzero value – you could also eliminate the member variable for the reference count for the class object (but not the objects and locks count global variable!).
IUnknown::QueryInterface
The QueryInterface implementation is 100 percent standard for this object – no special stuff because it's a class object. All we do is see whether the interface requested is one of the two interfaces (IUnknown and IClassFactory) that we support. If it is, we return an interface pointer, cast appropriately, to our object – and we call AddRef on that exact pointer to reference count. If not, we return the appropriate error code, E_NOINTERFACE.
STDMETHODIMP CMyClassObject::QueryInterface(REFIID iid, void ** ppv) {
*ppv = NULL;
if (iid == IID_IUnknown==iid || iid == IID_IClassFactory) {
*ppv = static_castthis;
(static_cast*ppv)->AddRef();
return S_OK;
else {
*ppv = NULL; // COM Spec requires NULL if failure
return E_NOINTERFACE;
}
}
Note the funky new static_cast operator. In ANSI C++, you can distinguish between the three different semantic uses of casts by using different operators. The static_cast operator does the appropriate cast between pointers to different class types, changing the value of the pointer if necessary (it's not in this case because I'm not using multiple inheritance).
IClassFactory::CreateInstance
Here is the heart of our class object – the function that creates instances.
STDMETHODIMP CMyClassObject::CreateInstance (IUnknown *pUnkOuter,
REFIID iid, void ** ppv)
{
*ppv=NULL;
// Just say no to aggregation.
if (pUnkOuter != NULL)
return CLASS_E_NOAGGREGATION;
//Create the object.
CMyObject *pObj = new CMyObject();
if (pObj == NULL)
return E_OUTOFMEMORY;
//Obtain the first interface pointer (which does an AddRef).
HRESULT hr = pObj->QueryInterface(iid, ppv);
// Delete the object if the interface is not available.
//Assume the initial reference count was zero.
if (FAILED(hr))
delete pObj;
return hr;
}
First off, we don't support aggregation, so if the pointer is non-NULL, we can't create the object because we're being asked to support aggregation. Next, we allocate the object and return E_OUTOFMEMORY if we can't allocate the object.
Next, we call QueryInterface on the newly created object to get an interface pointer to return. If this fails, we delete the object and return the error code. If it succeeds, we return the success code from QueryInterface. Note that QueryInterface will call AddRef if it succeeds, giving us a correct reference count for the object.
Note also that we did not increment the object and lock counter, g_cObjectsAndLocks. We could have done this if creation succeeded, but we would have to decrement it either in the instance object's Release or in its destructor. We'll put it in the destructor of the object itself – in Part 5. But if the decrement is in the destructor, then the increment should be in the constructor, not here.
There are a number of different patterns for doing the initial QueryInterface on the object, depending on how the object itself does its initial reference counting. An issue that comes up is that in some cases, an object will do something in the process of doing QueryInterface that causes the a pair of AddRef and Release calls to be executed. If the initial reference count of the object is zero, the call to Release will cause the object to free itself – even before CreateInstance returns. Not good.
One common technique is to set the object's initial reference count to one rather than zero. It's easy to do this in the object's constructor (see Part 5). If you do that, though, you have to modify CreateInstance to call Release after it calls QueryInterface so that the reference count will be set right.
If you do this, you omit deleting the object. If QueryInterface fails, it won't call AddRef, so the object's reference count will be one, not two. If you call Release at that point, the object's reference count will go to zero and the object will delete itself. If QueryInterface succeeds, it will increment the reference count to two and then the Release will decrement the reference count at one, where it should be for a healthy object.
If you assume that the initial reference count is one, you end up with CreateInstance code for the QueryInterface to the end that looks like this:
// ...
//Obtain the first interface pointer (which does an AddRef).
HRESULT hr = pObj->QueryInterface(iid, ppv);
// Delete object if interface not available.
// Assume the initial referece count was one, not zero.
pObj->Release(); // Back to one if QI OK, deletes if not
return hr;
}
We'll use this code for our object in Part 5: it's simple, and it always works. The good doctor doesn't consider it a disadvantage that CreateInstance has to know implementation details about the object – after all, that's what CreateInstance is for: to encapsulate such details so the client doesn't have to worry about them.
IClassFactory::LockServer
LockServer merely increments and decrements the global lock and object count. It does not attempt to release the DLL when the count goes to zero. (If this was an EXE server, the server would be shut down when the count went to zero, provided there weren't any interactive users.)
STDMETHODIMP CMyClassObject::LockServer(BOOL fLock) {
if (fLock)
InterlockedIncrement(&g_cObjectsAndLocks);
else
InterlockedDecrement(&g_cObjectsAndLocks);
return NOERROR;
}
Again, I've chosen to make this code thread safe. When the count goes to zero, the object can be deleted.
DllCanUnloadNow
COM will call DllCanUnloadNow to decide whether or not to unload a DLL. We simply return S_OK if it's okay to unload, S_FALSE if not. It's okay to unload if there are no objects or locks on the server.
STDAPI DllCanUnloadNow() {
if (g_cObjectsAndLocks == 0)
return S_OK;
else
return S_FALSE;
}
Where we've been; where we're going
So we've discussed part of how in-process objects are created and ways of making that creation more efficient. We also talked about the class object (also known as class factories) and how to implement one. But we didn't get around to actually implementing an object.
In Part 5, we'll talk about the guts of implementing an instance object, including the code you need for IUnknown and your own custom interfaces – and maybe even talk about special high-efficiency COM objects that don't use COM to be created.
A note: We've been using C++ to do these implementations, but you can also use C. The good doctor doesn't see any reason to (especially since mixed C and C++ programs are fine). But if you really want to for some reason, there are examples on MSDN, including the topic, "RectEnumerator in C: ENUMC.C," in Chapter Two of Inside OLE.
Part 5: Implementing an Object
In Part 4, we talked about how in-process objects are created, and ways of making that creation more efficient. We also talked about the class object (also known as class factory) and how to implement one. Now, we'll talk about implementing your actual object. In Part 6, we'll talk about creating and using these COM objects we've written.
Dr. GUI's expanding bookshelf
Dr. GUI has recently bought two good books on ATL. The good doctor prescribes both of them for his patients who are learning ATL.
The first is from Wrox Press, entitled Beginning ATL COM Programming (see the World of ATL Web site at http://www.worldofatl.com/BegATLCOM/begAtlCom.htm). It's by Grimes, Stockton, Reilly, and Templeman. You might think the names sound like a law firm, but a quick look at the authors' pictures on the cover will dissuade you from that notion. This book does a very nice in-depth job of introducing you to ATL programming. There's also a lot of ATL information at the World of ATL Web site (http://www.worldofatl.com).
The second book is from MIT Press and is entitled Active Template Library: A Developer's Guide (see the IDG Books Worldwide Web site at http://www.idgbooks.com/cgi-bin/db/fill_out_template.pl?idgbook:1-5585-1580-1:book-idg::uidg2896). It's by Tom Armstrong, who doesn't sound like a law firm. There's no picture of him available, so I can't tell if he looks like an attorney or not. This book isn't always as detailed as the Wrox book, but it covers considerably more material – so both are worth having.
Implementing the object itself
In Part 4, we showed the class object, which implements IClassFactory. You'll recall in the CreateInstance method, we called new to create that actual instance:
CMyObject *pObj = new CMyObject();
But we never discussed what that object does or how it's created. That's what's coming up next.
The design of CMyObject
Our object will implement four interfaces: IFoo, IFoo2, IGoo, and, of course, our good friend IUnknown. (There's got to be some religious significance in the idea that the IUnknown is a part of all objects.)
IFoo2 is an extension of IFoo (IFoo plus a new function), while IGoo is a totally separate interface. So our CMyObject diagram will look like this:
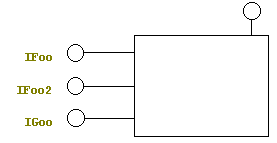
Figure 8. CMyObject, which supports four interfaces
Note that, as the diagram implies, COM – specifically QueryInterface – does not consider IFoo and IFoo2 to be related at all – nor, for that matter, does it consider the interfaces to be related to IUnknown. When you ask for IUnknown, you get IUnknown. And when you ask for one of the other interfaces, you get just it. Remember that an interface is the only way a client deals with an object ever.
As you might recall from Part 2 of this series on COM and ATL, the macro-ized version of IFoo was:
interface IFoo : IUnknown {
STDMETHOD Func1(void) PURE;
STDMETHOD Func2([in] int nCount) PURE;
};
But let's get into the habit of using IDL for defining our interfaces. So the IDL for this interface would look like this. (Note: Your GUIDs should vary . . . .)
[
uuid(7BA998D0-C34F-11D1-A54D-0000F8751BA7)
]
interface IFoo : IUnknown
{
HRESULT Func1();
HRESULT Func2(int inonly);
};
The second interface-independent interface, IGoo, looks like this in IDL:
[
uuid(0E02B134-C350-11d1-A54D-0000F8751BA7),
]
interface IGoo : IUnknown
{
HRESULT Gunc();
};
The weird interface is IFoo2. Because it's extending IFoo, we derive IFoo2 from IFoo.
[
uuid(62F890DA-C361-11d1-A54D-0000F8751BA7)
]
interface IFoo2 : IFoo
{
HRESULT Func3([out, retval] int *pout);
};
Note IFoo2 comprises six methods: the three IUnknown methods, the two IFoo methods, and Func3. (By the same token, IFoo and IGoo comprise five and four methods, respectively – never forget the omnipresent IUnknown!)
What do these methods do? Well, we should document our interfaces, so let's do it.
When the object is created, it will have an internal value of 5. Func1 will increment the internal value, and beep if the new value is a multiple of 3. Func2 will set the internal value to the parameter you pass in.
You note that we forgot to provide a way to read the internal value. Silly us! But it often happens that you need to add functionality to an existing interface. To do this we define a new interface, IFoo2, which is derived from IFoo. IFoo2 adds Func3, which gets the current internal value. Since we used the "retval" attribute as well as the "out" attribute, languages that recognize "retval" (Visual Basic and Visual J++, at least) will use this value as the return value from the function. So in Visual Basic, we call this function by saying "Text2 = Foo2.Func3" rather than "Foo2.Func3(Text2)".
We also wanted our object to have beep on demand capabilities, so we added the IGoo interface with its method, Gunc, which beeps. Note that we've designed IGoo so it's not dependent on the state of the internal value at all – only IFoo and IFoo2 deal with that value. That means that any object can implement IGoo without either of the IFoo interfaces – and vice versa. In other words, these interfaces are not linked.
Implementing multiple interfaces using multiple inheritance
So our object is implementing a total of four interfaces: IFoo, IFoo2, IGoo, and IUnknown. Now, as long as our implementation of QueryInterface returns valid interface pointers for each of these interfaces, it doesn't matter how precisely we implement our code. For instance, if you write COM objects in C, you'd create an array of function pointers (same memory format as a vtable) and QueryInterface would return the address of a pointer that pointed to the vtable (same memory format as an object with a vtable pointer at offset zero). This is complicated, so Dr. GUI does not prescribe C for his patients who write COM objects.
In C++, there are also a variety of methods. One method is to have each interface implemented by a separate object. QueryInterface then just passes back a pointer to the appropriate object. A variation on this theme is to have these separate objects be members of the main object, created using classes nested within the main object. MFC uses this method internally. The cleanest method, however, is to just inherit from each of the interfaces your object will implement. ATL uses this method, as does our code here. All QueryInterface has to do is to return the pointer after casting it to the appropriate base class.
So our implementation class declaration looks like this:
class CMyObject :
public IFoo2,
public IGoo
{
private:
int m_iInternalValue;
ULONG m_refCnt;
public:
CMyObject();
Virtual ~CMyObject();
// IUnknown
STDMETHODIMP QueryInterface(REFIID, void **);
STDMETHODIMP_(ULONG) AddRef(void);
STDMETHODIMP_(ULONG) Release(void);
// IFoo
STDMETHODIMP Func1();
STDMETHODIMP Func2(/*[in]*/ int inonly);
// IFoo2
STDMETHODIMP Func3(/*[out, retval]*/ int *pout);
// IGoo
STDMETHODIMP Gunc();
};
Note that we don't explicitly inherit from IUnknown or IFoo. We don't have to inherit from IFoo because IFoo2 inherits from IFoo. By the same token, we don't have to inherit from IUnknown because both IFoo2 and IGoo inherit (directly or indirectly) from IUnknown.
If you inherit from IFoo or IUnknown directly, you'll create ambiguities and get the appropriate compiler errors. So the rule is: inherit only from the most-derived classes – if another class that your object is implementing inherits from a base class you're also implementing, don't inherit from the base class. You'll still get to implement all of the methods in the base class (in fact, you must implement all of the methods).
Why MI works for the IUnknown methods
Take a look at the inheritance diagram for our object:
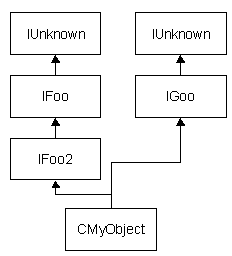
Figure 9. The object's inheritance
Note There are two inheritance paths for IUnknown. How can this work? Will we have more than one reference count? Will our world fall apart?
If we were inheriting implementation of IUnknown, we'd be in deep trouble – we would have two implementations of IUnknown for the same object. (If we inherited from more interfaces, we'd have more.) But we're not: IUnknown has neither data nor functions, so we're only inheriting the interface.
When you inherit only the interface for a class, you normally write only one implementation for those functions, typically in the most-derived class. So we'll just write one implementation of QueryInterface, AddRef, and Release, and that will be in CMyObject.
All of the IUnknown vtable pointers will point to the same QueryInterface, AddRef, and Release functions. This is entirely consistent with virtual function behavior in C++: when you call a virtual function, you always call the most-derived implementation available. So the vtable for CMyObject might look something like this:
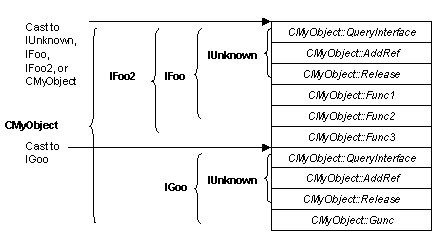
Figure 10. A possible implementation of a vtable for CMyObject (your compiler may vary).
Note All of the vtable pointers, even the ones in IGoo's IUnknown section, point to CMyObject functions – that's how we're always sure to call the most-derived implementation.
So you've noticed that the one implementation of QueryInterface, AddRef, and Release satisfies all of the interfaces from which we've inherited. This is very handy for IUnknown, but it is not the right thing to do for unrelated interfaces that happen to have methods with the same signature. If you implement your COM object with multiple inheritance, the one method you write will be called for both interfaces. This is the one major downside of implementing COM objects using multiple inheritance. Thankfully, it doesn't come up often – and when it does, you can solve the problem by implementing one of the interfaces using a nested class while using multiple inheritance for the rest of the object.
Figure 11 is a diagram of a CMyObject object.
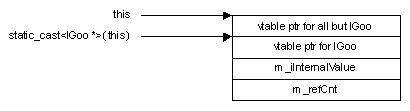
Figure 11. A CMyObject object.
Casting the this pointer to IUnknown *,
IFoo *, IFoo2 *, or
CMyObject * doesn't change the value – only casting to
IGoo * changes the value. Therefore, we pass back the
this pointer cast to IFoo2 * when we do
QueryInterface for IUnknown,
IFoo, or IFoo2. This pointer points to
the vtable pointer that points to the beginning of the
vtable. When QueryInterface is called for
IGoo, we cast the this pointer to
IGoo *, thereby modifying our copy of the
this pointer to point to the second vtable pointer
in the object.
Implementing QueryInterface
So now that we know what QueryInterface is going to do and why it'll work, let's look at the code:
STDMETHODIMP CMyObject::QueryInterface(REFIID iid, void **ppv)
{
*ppv = NULL;
if (iid == IID_IUnknown ||
iid == IID_IFoo ||
iid == IID_IFoo2)
{
*ppv = static_cast<IFoo2 *>(this);
}
else if (iid == IID_IGoo)
{
*ppv = static_cast<IGoo *>(this);
}
if (*ppv) {
AddRef();
return S_OK;
}
else return E_NOINTERFACE;
}
We call AddRef if QueryInterface succeeds – whenever you give out an interface pointer, you must AddRef it (and the client must Release it when it's done).
Note that when the client requests IID_IGoo, we're
calling AddRef with a different pointer than we return
to the client. In order to support per-interface reference counting, COM
clients must call AddRef and
Release on the correct interface pointers. Since we
have appropriate knowledge of the way reference counting is implemented
for this object (we're doing the implementation, after all), we can
relax that requirement for QueryInterface since we know
that just calling this->AddRef() will reference count
correctly. In a more complicated situation, such as a tear-off interface
implemented by a temporary object or an interface implemented by a
nested class, we might not be able to make this simplification.
Implementing AddRef and Release
After all of that, our AddRef and Release implementations are easy:
STDMETHODIMP_(ULONG) CMyObject::AddRef(void)
{
return ++m_refCnt; // NOT thread-safe
}
STDMETHODIMP_(ULONG) CMyObject::Release(void)
{
--m_refCnt; // NOT thread-safe
if (m_refCnt == 0) {
delete this;
return 0; // Can't return the member of a deleted object.
}
else return m_refCnt;
}
If we were supporting multithreaded operation, we'd have to use InterlockedIncrement and InterlockedDecrement. Just using the increment and decrement operators is more efficient, so we'll use these for now. (ATL makes the most efficient possible choice automatically when you tell it which threading model to use.)
In addition to decrementing the reference count, Release has the responsibility of destroying the object when the reference count goes to zero. If it does this, it must return zero to indicate that the object no longer exists.
The Constructor and Destructor
Here's the code for the constructor and destructor:
CMyObject::CMyObject() : m_iInternalValue(5), m_refCnt(1)
{
g_cObjectsAndLocks++; // NOT thread-safe
}
CMyObject::~CMyObject()
{
g_cObjectsAndLocks--; // NOT thread-safe
}
As you might expect, the constructor initializes the internal value of the member variables – in this case, setting m_iInternalValue to five.
In addition, the constructor and destructor have two little tricks. First, the constructor initializes the object with a reference count of one, not zero. We account for this in CMyClassObject::CreateInstance, which calls Release on the object after it does the first QueryInterface. If the first QueryInterface succeeds, it calls AddRef, which increments the reference count, leaving it at two. If it fails, AddRef isn't called, so the reference count stays at one. In either case, CreateInstance calls Release, which decrements the count. If the first QueryInterface succeeded previously, the reference count is then one; if it failed, the reference count goes to zero and Release deletes the object. Recall our implementation of IClassFactory::CreateInstance:
STDMETHODIMP CMyClassObject::CreateInstance(IUnknown *punkOuter,
REFIID iid, void **ppv)
{
*ppv=NULL;
if (punkOuter != NULL) // Just say no to aggregation.
return CLASS_E_NOAGGREGATION;
//Create the object.
CMyObject *pObj = new CMyObject();
if (pObj == NULL)
return E_OUTOFMEMORY;
//Obtain the first interface pointer (which does an AddRef).
HRESULT hr = pObj->QueryInterface(iid, ppv);
// Delete the object if the interface is not available.
// Assume that theinitial reference count was one, not zero.
pObj->Release(); // back to one if QI OK, deletes if not
return hr;
}
The second little trick is that the constructor and destructor increment and decrement the global objects and locks count. This count is initialized to zero when the DLL is loaded and incremented for each object created (except the class object) and when IClassFactory::LockServer(TRUE) is called. It's decremented when each object is destroyed and when LockServer(FALSE) is called. The good doctor feels it's more sanitary to increment in the constructor and decrement in the destructor since one normally expects opposite actions to be performed in these two functions. It's of course possible to increment in CreateInstance and decrement if you delete the object in Release, but it doesn't seem so elegant to have these related functions done in two separate objects.
For an in-process server, this reference counter is only used by the global function DllCanUnloadNow:
STDAPI DllCanUnloadNow() {
if (g_cObjectsAndLocks == 0)
return S_OK;
else
return S_FALSE;
}
You never call DllCanUnloadNow – rather, COM calls it when it's thinking of unloading unused servers. However, you can request that COM unload unused servers by calling CoFreeUnusedLibraries. You might do this when you know that you've freed up some in-process servers, for instance.
The situation is different for out-of-process servers – they're required to free themselves by ending their process.
Implementing your custom interface
Now that we've got all the COM overhead out of the way, it's trivial to implement our methods:
STDMETHODIMP CMyObject::Func1()
{
m_iInternalValue++;
if (m_iInternalValue % 3 == 0) MessageBeep((UINT)-1);
return S_OK;
}
STDMETHODIMP CMyObject::Func2(/* [in] */ int inonly)
{
m_iInternalValue = inonly;
return S_OK;
}
// IFoo2
STDMETHODIMP CMyObject::Func3(/* [out, retval] */ int * pout)
{
MessageBeep((UINT)-1);
*pout = m_iInternalValue;
return S_OK;
}
// IGoo
STDMETHODIMP CMyObject::Gunc()
{
MessageBeep((UINT)-1);
return S_OK;
}
There's nothing surprising about these functions at all – they just do what we said they'd do. I added the [out, retval] comment to Func3 to remind folks of how the IDL is declared. Do note that the real return value is always the HRESULT for all COM methods.
Building it
As it turns out, it's pretty easy to build the application. For this simple object, the good doctor just put the declarations for both of the classes in the same header and the code for the two classes in the same .CPP files. The only other files you have to write is the IDL file and the linker .DEF file.
We've written most of the IDL file already, but we need to some code to the beginning:
import "oaidl.idl";
import "ocidl.idl";
And some code to the end, after the interface definitions:
[
uuid(7BA998C3-C34F-11D1-A54D-0000F8751BA7)
]
library NONATLOBJECTLib
{
importlib("stdole32.tlb");
importlib("stdole2.tlb");
[
uuid(2E98593E-C34A-11D1-A54D-0000F8751BA7)
]
coclass MyObject
{
[default] interface IFoo;
interface IFoo2;
interface IGoo;
};
};
The first GUID (starting with 7BA9) is the GUID for the type library; the second one (starting with 2E98) is the CLSID for this object.
Note that we didn't create the header file for the interfaces. MIDL takes care of that for us when we run it from the command line:
midl /Oicf /h "NonATLObject.h" /iid "NonATLObject_i.c"
"NonATLObject.idl"
You can make this the custom build step for your IDL file if you like. MIDL will create several files for us:
- A type library, NonATLObject.TLB, which our clients can use
- The proxy/stub file (more on this another time)
- A header file, NonATLObject.h
- A file that contains the code necessary to define our GUIDs (IIDs and CLSID): NonATLObject_i.c
We then include NonATLObject.h in our .CPP file before including our header. This header automatically includes all of the Windows and COM headers we're likely to need. By including it before our header, we eliminate the need to include it in our header.
We also need to include NonATLObject_i.c in exactly one of our .CPP files – it contains the definitions for all of our GUIDs. And we define the global class object and the objects and locks counter. So our includes and definitions look like this:
#include "NonATLObject.h"
#include "MyObject.h"
#include "NonATLObject_i.c"
// The global class object.
CMyClassObject g_cfMyClassObject;
// The count of locks and objects.
ULONG g_cObjectsAndLocks = 0;
// Class members and Dll* functions next
Finally, we define our member functions for both classes, and DllGetClassObject (described in Part 4) and DllCanUnloadNow.
Once we build the server, we register it as described in Part 3, substituting the correct GUID.
Using it
This time, we implemented a complete COM object. In Part 6 we'll talk about how to use our object from Visual Basic, Visual J++, and two ways from Visual C++. But, in case you want to get a head start, you'll find that the type library (the .TLB file) produced by MIDL is essential to letting Visual Basic, Visual J++, and even Visual C++ 5.0 know how to access your new object.
Part 6: Using Our COM Object in Visual Basic and Visual J++
In Part 5, we implemented a complete COM object. Now, we'll talk about using that object from Visual Basic and Visual J++. (We'll do C and C++ next time.) Some of you have written saying, "I don't care about implementing COM objects; I just want to use them." You now have your wish.
But first, an update
Brent Rector pointed out something that I overlooked in our object's QueryInterface function. He noticed that I went ahead and set *ppv to NULL without checking to insure that ppv wasn't NULL.
STDMETHODIMP CMyObject::QueryInterface(REFIID iid, void **ppv)
{
*ppv = NULL;
// ...
The good doctor initially argued that that was okay – if ppv was NULL, the result would be a general protection (GP) fault. You'd surely catch this flaw in testing – and that might be preferable to just returning an error result that would be ignored.
Well, if your object is only an in-process server (that is, a DLL), that might be okay. After all, the process that dies as a result of the GP fault would be the client process, which by all rights should die because it had the audacity to pass a NULL pointer to QueryInterface. How rude! Serves it right! (Besides, Dr. GUI hates taking the time unnecessarily to execute code to check for errors.)
The problem occurs when the object is implemented out-of-process (in an EXE). In that case, the process that dies would be the server process, not the client. And that would not be cool – especially if the server was providing other objects to other processes and/or running stand-alone at the same time. (Having Microsoft Word crash because some background process passed a NULL pointer to QueryInterface would not be fun.) It would be even worse if the server was on a remote machine.
So, to make a long story short, Dr. GUI's come to agree with Brent that the additional error checking is necessary. So we add a line to our old QueryInterface method, and it becomes:
STDMETHODIMP CMyObject::QueryInterface(REFIID iid, void **ppv)
{
if (ppv == NULL) return E_INVALIDARG; // Don't crash!
*ppv = NULL;
// ...
Using Our Object from Visual Basic
Using our object from Visual Basic couldn't be easier.
First, we have to add a "reference" to our object to our Visual Basic project. Using the References... command on the Projects menu, we add the reference by finding our COM object in the list box and checking it, as shown in Figure 12.
Figure 12. Adding the reference to our COM object
Then we design a simple form with a button to call each method and a text box to show the current value, such as the form in Figure 13.
Figure 13. A form to call each method
Finally, we write the code necessary to access the object. First, in the general declarations section, we declare a reference to the object:
Private obj As MyObject
We then create the actual object in the Load method for the form:
Private Sub Form_Load()
Set obj = New MyObject
End Sub
This causes Visual Basic to call CoCreateInstance to create the object.
Now that the object's been created, we add a button handler to call the Func1 and Func2 methods in the default IFoo interface:
Private Sub Func1IncBeep3_Click()
obj.Func1
End Sub
Private Sub Func2Set_Click()
If IsNumeric(Text1) Then obj.Func2 (Text1)
End Sub
To call methods in other interfaces, we have to get access to the interface. We do this by creating a variable of the correct type for the interface, then setting it to point to the object. (When you do this, Visual Basic actually calls QueryInterface on the object.) To switch interfaces, we use code like this:
Dim Foo2 As IFoo2 ' Switch interfaces
Set Foo2 = obj
We can then call IFoo2 methods using the Foo2 object reference.
Knowing this, we can understand the code for accessing the other methods of the object:
Private Sub Func3BeepGet_Click()
Dim Foo2 As IFoo2 ' Switch interfaces
Set Foo2 = obj
Text1 = Foo2.Func3
End Sub
Private Sub GuncBeep_Click()
Dim Goo As IGoo ' Switch interfaces
Set Goo = obj
Goo.Gunc
End Sub
Finally, we add a button handler for the Increment Text Box method:
Private Sub IncTextBox_Click()
If IsNumeric(Text1) Then Text1 = Text1 + 1
End Sub
It almost couldn't be easier.
If you're a fan of late binding, take note: you could use late binding to access this object, but you'd only be able to access the default (IFoo) interface. Late binding doesn't work well for objects that use multiple interfaces – and it's always slower. (By the way, it might be wise to make IFoo2 the default interface at least, since it implements all of the functionality of IFoo as well as Func3.)
Using Our Object from Visual J++
It's almost as easy to use our object from Visual J++. First, we have to create a special .class file that represents the COM object. We do this with the Java Type Library Wizard on the Tools menu of Microsoft Visual Studio. Again, we just select our object and check it, as shown in Figure 14.
Figure 14. Selecting our COM object in the Java Type Library
This results in a .class file created in our trustlib directory (in the same subdirectory as other Java classes). Our results window has the import statement we copy and paste into our .java file. It also has a reference to the summary.txt file that contains a Java textual representation of our class library. Do not compile this file; the .class file has already been created.
In our case, the import statement reads "import nonatlobject.*;". We insert this at the top of our .java file.
Once we've done this import, we can create and use the object.
Creating the object is as simple as calling new:
IFoo myObj = new MyObject();
Note that we created a MyObject object but assigned it to an IFoo object reference. We cannot use the object as a MyObject in Visual J++ because it doesn't recognize or support the concept of a default interface.
At this point, we can call the IFoo methods:
myObj.Func2(5); // Sets
myObj.Func1(); // Increments and beeps
myObj.Func1(); // Increments
myObj.Func1(); // Increments
If we want to call the IFoo2 or IGoo methods, we have to create new object references and assign the object to them:
IFoo2 myFoo2 = (IFoo2)myObj;
System.out.println("Value is " + myFoo2.Func3() + " (8?)");
IGoo myGoo = (IGoo)myFoo2;
myGoo.Gunc(); // Beeps
As you can see, using a COM object from Visual J++ is almost as easy as using it from Visual Basic.
Where we've been; where we're going
This time, we learned how to use our COM object from Visual Basic and Visual J++. In Part 7, we'll learn how to use it from C++ and perhaps even from C.
Part 7: Using Our Object from Visual C++
In Part 6, we showed how to use our COM object from Visual Basic and Visual J++. This time, we'll show how to use it from C++ and from good old C. Next time, we'll show how to use the new Visual C++ 5.0 smart COM pointer class to make using COM objects as easy as in Visual Basic.
Using Our Object from Visual C++: The Old Way
Getting the definitions right
As it turns out, it isn't terribly hard to use your object from C++ directly – but there are a few key things to remember.
First off, you'll recall that when you built your object, the MIDL compiler produced a header file that was named the same as the base name of the IDL input file but had an .h extension. (For instance, running MIDL on MyObject.IDL produces the header MyObject.h.) We used this file when we built the control; we'll also use it for building the client. MIDL also produced a file of data definitions for our GUIDs. This file is named by appending "_i.c" to the base name of the MIDL file. In our example, the definitions file would be named MyObject_i.c.
We have to #include the header file as follows:
#include "MyObject.h"
Rather than including the MyObject_i.c file, add it to the project as a source file so it will be compiled and linked into your client project.
Initializing and uninitializing COM in C++
Before we can use any COM objects, we have to initialize the COM libraries for our thread by calling CoInitialize. And before our program exits, we'll have to call CoUninitialize.
The NULL argument is a required dummy argument. Note that we check the return value of CoInitialize as follows:
HRESULT hr = CoInitialize(NULL);
if (FAILED(hr)) {
cout << "CoInitialize Failed: " << hr << "\n\n";
exit(1);
}
else {
cout << "CoInitialize succeeded\n";
}
Calling exit is pretty severe (note that this is a command-line program, not a Windows application), but Dr. GUI figures if the COM libraries won't initialize, what's the point of running the program at all?
You may not agree with what the good doctor did, but he put a label on the CoUninitialize call so he could jump to it using a goto if creating the object failed. You can do this with nested if statements if you prefer.
// ... rest of program...
Uninit:
CoUninitialize();
} // end main()
Note that you may need to call CoInitializeEx if your application is multithreaded and wants to use objects that support the free-threaded model. (More on threading models another time.) Since CoInitializeEx is only supported if COM multithreading is supported (Windows NT 4.0 and later and Windows 95 with the DCOM add-in), and since we don't need multithreading, we'll stick with CoInitialize.
We don't need to explicitly include the COM headers since the header file that MIDL generated for us automatically includes them.
Creating the object in C++
Once the COM libraries have been initialized, we can create our object:
IFoo * pIFoo;
hr = CoCreateInstance(CLSID_MyObject, NULL, CLSCTX_ALL,
IID_IFoo, reinterpret_cast<void **>(&pIFoo));
if (FAILED(hr)) {
cout << "CoCreateInstance Failed: " << hr << "\n\n";
goto Uninit;
}
else {
cout << "CoCreateInstance succeeded\n";
}
The MIDL-generated header takes care of all the declarations: the IFoo interface pointer type, and GUIDs for the class ID, and the interface ID. It's a very handy file!
Next, we call CoCreateInstance. The parameters could use a bit of explanation.
CLSID_MyObject is the class ID for this object. The NULL pointer in CoCreateInstance would non-NULL if we were "aggregating" this object into another object. (We may discuss aggregation another time if there's demand for it.) CLSCTX_ALL means that we don't care whether the object is in-process or out-of-process. If we wanted to insist on using a particular type of server, we'd use another value from the CLSCTX enumeration.
In COM, we never have a pointer to an object; instead, we have a pointer to one of the object's interfaces. Because of this, we have to specify what interface we want when we create the object. In this case, we ask for the IFoo interface by passing IID_IFoo as the penultimate parameter.
The final parameter is a pointer to where to store the interface pointer returned by CoCreateInstance. If the creation fails (either the object couldn't be created or the interface requested wasn't available), NULL is written into this pointer. The newer reinterpret_cast operator is the best way to cast the interface pointer's address to a void ** pointer – reinterpret_cast makes it clear that our intention is to simply view the bits in the pointer as a different type without attempting to change the value in any way.
We check the HRESULT to see whether or not the creation succeeded. If it didn't, we jump to the CoUnitialize call.
Calling methods of the interface in C++
Calling the methods of the interface is trivial: just make the call with the interface pointer, as below.
pIFoo->Func1();
It couldn't be easier! Note that we're not checking the HRESULT here, although we should. In an in-process server, it isn't crucial because the only time a call will fail is if the method explicitly returns an error. I know that this method doesn't, so we're OK.
But in the general case, there are other reasons why the call may fail even though the method doesn't return a failure code. For instance, if the server is a remote server, the network may fail. You (as the client) would be notified of this failure by an appropriate value in the HRESULT when you call a method. Even an out-of-process server on the same machine can fail if it crashes – and the HRESULT could reflect this.
So, for the sake of robustness, we should check the HRESULT of every call with code that looks like this:
hr = pIFoo->Func1();
if (FAILED(hr)) DoSomethingAboutIt();
// Etc.
Changing interfaces in C++
Our component exposes its functionality through three different interfaces (four, counting IUnknown). So to fully use the component, we'll have to get an interface pointer to another interface. This is what QueryInterface is for:
IGoo *pIGoo;
hr = pIFoo->QueryInterface(IID_IGoo,
reinterpret_cast<void **>(&pIGoo));
if (FAILED(hr)) {
cout << "QI Failed: " << hr << "\n\n";
goto ReleaseIFoo;
}
else {
cout << "QI succeeded\n";
}
We pass QueryInterface the ID of the new interface and a pointer to the pointer in which to store the new interface pointer. If it fails, we jump to the code that releases the IFoo pointer and calls CoInitialize. (See below.)
After we call QueryInterface, we can call methods on the IGoo interface as above:
pIGoo->Gunc();
Again, we should be checking for errors as above.
Cleaning up: Releasing the interfaces and calling CoUninitialize in C++
Now that we've used the object, we're ready to end – but before we do, we have to clean up after ourselves by releasing both of the interface pointers we're holding.
cout << "All done!\n";
pIGoo->Release();
ReleaseIFoo:
pIFoo->Release();
Uninit:
CoUninitialize();
} // end main()
The labels and gotos are so we only do the necessary cleanup if there's an error – at any point, if there's an error, we can only clean up what we've done, not what we've yet to do.
Using Our Object from C: The REALLY Old Way
It's rather esoteric, but it is in fact possible to use COM components from C. We're showing this not so much because Dr. GUI recommends it (or even expects you'll do it). Rather, we're showing it as a way for you to deepen your understanding of C, C++, and COM.
Using COM components from C involves simulating the vtable and virtual function calls that C++ does. This is fairly simple, but tedious, in C. Thankfully, the MIDL-generated header file takes care of most of the problem.
Converting the code back to C
Of course, we had to change all of the cout << "Output"; statements to printf calls. And we had to go back to the old (void **) cast operator since reinterpret_cast isn't available in C. That was tedious, but not life-threatening.
The hardest part of converting the example above into C was the agony of having to put up with C's restrictions. All of the variable declarations had to be moved to the beginning of the block. And there's no reference type in C, so we had to add ampersands (&) in front of all of the GUIDs in function calls. And we had to say "struct IFoo" instead of just "IFoo", as you can in C++. Still, you'll recognize the code pretty easily.
Note that we use the exact same header file and link with the exact same definitions file as in the C++ case. How can we use the same header? A quick check of the MIDL-generated header file reveals that it's full of conditional compilation blocks of the form:
#if defined(__cplusplus) && !defined(CINTERFACE)
// C++ code
#else
// C code
#endif
The __cplusplus symbol is defined automatically when you're compiling C++ code – it's not defined otherwise. In other words, the fact that we're including the file into a C module means that we're compiling the proper code. Note that the second half of the condition gives you a way to use C definitions even if you're compiling a C++ program – just #define CINTERFACE before you include the header.
Data types to simulate C++ vtables and objects in C
This "proper code" can look pretty weird because we have to come up with C data structures that correspond with a C++ class, including the vtable. For example, here's the C code MIDL generated for our IFoo vtable format:
typedef struct IFooVtbl
{
BEGIN_INTERFACE
HRESULT ( STDMETHODCALLTYPE __RPC_FAR *QueryInterface )(
IFoo __RPC_FAR * This,
/* [in] */ REFIID riid,
/* [iid_is][out] */ void __RPC_FAR *__RPC_FAR *ppvObject);
ULONG ( STDMETHODCALLTYPE __RPC_FAR *AddRef )(
IFoo __RPC_FAR * This);
ULONG ( STDMETHODCALLTYPE __RPC_FAR *Release )(
IFoo __RPC_FAR * This);
HRESULT ( STDMETHODCALLTYPE __RPC_FAR *Func1 )(
IFoo __RPC_FAR * This);
HRESULT ( STDMETHODCALLTYPE __RPC_FAR *Func2 )(
IFoo __RPC_FAR * This,
int inonly);
END_INTERFACE
} IFooVtbl;
BEGIN_INTERFACE and END_INTERFACE are defined as nothing on most platforms, including Windows. So what we really need to look at are the members of this structure.
Notice that there's one member for each method in the interface, including the IUnknown methods. The type of each member is the appropriate function pointer type. The name of each member is the name of the method. Note that the values of the members are undefined – this structure is merely a "template" (not a C++ template) that's placed "over" the vtable that's provided by the object. (If you implement your COM object in C++, you have to provide a filled-in structure as your vtable.) This structure insures that your calls match the method prototypes.
Note that each of the methods has an additional parameter called
"This". (An initial capital letter is used so the compiler won't get
confused with the C++ keyword this in the event that you
compile C-style COM usage with a C++ compiler.) You have to pass the
This pointer parameter explicitly in C – it's passed
automatically in C++. Any additional parameters come after
This, as above.
The interface is defined as a structure that contains a pointer to the vtable, as follows:
interface IFoo // interface is #defined as struct
{
CONST_VTBL struct IFooVtbl __RPC_FAR *lpVtbl;
};
CONST_VTBL is simply "const." This structure contains one member: a pointer to the vtable. Note that this is exactly what a C++ object with no data contains: a pointer to the class's vtable. Again, there is no data initialization. The data is provided by the object and we're simply interpreting the type of that data in C.
Initializing COM and creating our object in C
Initializing COM and creating our object in C looks almost like doing it in C++. Note that the variables are declared at the top; note further that we have to use the "struct" keyword for interface pointer declarations since we're actually declaring a pointer to a structure.
After that, we call CoInitialize and CoCreateInstance almost as normal. Note that we have to explicitly pass addresses of the GUID structures to CoCreateInstance – C doesn't have a reference type.
HRESULT hr;
struct IFoo *pIFoo;
struct IGoo *pIGoo;
printf("Hello, world!\n\n");
hr = CoInitialize(NULL);
if (FAILED(hr)) {
printf("CoInitialize Failed: %x\n\n", hr);
exit(1);
}
else {
printf("CoInitialize succeeded\n");
}
hr = CoCreateInstance(&CLSID_MyObject, NULL, CLSCTX_ALL,
&IID_IFoo, (void **)&pIFoo);
if (FAILED(hr)) {
printf("CoCreateInstance Failed: %x\n\n", hr);
goto Uninit;
}
else {
printf("CoCreateInstance succeeded\n");
}
Again, we used gotos for errors. And, again, if you don't like it, you can use nested "if" statements instead.
Calling methods on our object in C
Where you really pay the price for using C is in the awful code you have to write to call methods. When you do a C++ virtual function call, the compiler handles the double indirection and the this pointer for you. When you use C to simulate a virtual function call, you have to write it out yourself:
pIFoo->lpVtbl->Func1(pIFoo);
This code takes a bit of explanation. First, recall that piFoo is our interface pointer – it points to a hunk of memory (in the object, actually) that contains a vtable pointer. In the structure declaration above, the name of the member that points to the vtable is lpVtbl.
So the first indirection gets us to the structure, and the second indirection gets us to the vtable. Recall that we've defined the vtable as a structure that contains a set of function pointers. One of those pointers is called Func1; so we use that pointer now to call the function in the vtable. (You don't have to explicitly dereference the function pointer in C or C++, so the syntax is simpler than it could be.) Because the type of the function pointer includes the types of the parameters and return type, we're assured that the function will be called with the right types.
If you declare a preprocessor symbol called COBJMACROS before you include the header, you'll also get a macro for each method in the interface. The macros are of the form:
#define IFoo_Func1(This) \
(This)->lpVtbl -> Func1(This)
We can then make the call below instead of the ugly call above:
IFoo_Func1(pIFoo);
It isn't as elegant as C++, but it's better than the other syntax.
Changing interfaces in C
Changing interfaces in C is almost as easy as in C++:
hr = pIFoo->lpVtbl->QueryInterface(pIFoo,
&IID_IGoo, (void **)&pIGoo);
if (FAILED(hr)) {
printf("QI Failed: %x\n\n", hr);
goto ReleaseIFoo;
}
else {
printf("QI succeeded\n");
}
Note that we have to do the funky function call, including explicitly providing the this pointer. If we're using the COBJMACROS, we could replace the QueryInterface call above with:
IFoo_QueryInterface(pIFoo, &IID_IGOO, (void **)pIGoo);
Cleaning up: Releasing the interfaces and uninitializing in C
Aside from the calling syntax, cleaning up when we're done is the same as in C++:
IGoo_Release(pIGoo);
ReleaseIFoo:
pIFoo->lpVtbl->Release(pIFoo);
Uninit:
CoUninitialize();
Notice that I mixed the two syntaxes for calling Release. You can use either with either interface pointer.
Where we've been; where we're going
This time, we've seen how to use our COM object from C++ and C. In Part 8, we'll talk about the way-cool Visual C++ 5.0 smart pointers for COM objects and show how to make using a COM object from Visual C++ 5.0 as easy as using it from Visual Basic.
Part 8: Get Smart! Using Our COM Object with Smart Pointers
We've covered writing our basic COM object and using it from Visual Basic, Visual J++, Visual C++, and even C. After this column on using COM objects via VC++ 5.0 smart COM pointers, we'll start discussing the best way to write small, high-performance COM objects: the Active Template Library, or ATL.
Using Our COM Object via Smart Pointers: #import-ing Your typelib
If you're using Visual C++ 5.0 or later, you have access to a very cool feature: smart pointers for COM objects that make using them as easy as in Visual Basic and easier than in Visual J++.
These smart pointers are created when you use the new
#import directive to "import" a type library. When you use
#import, the Visual C++ compiler reads the type library
from the file you specify. This file can be any file that contains a
type library that can be read with the LoadTypeLib API.
Usually the file will be a .TLB, .ODL,
.EXE, .DLL, or .OCX, but it could
be any file type that LoadTypeLib can read.
All you really need to do is to use #import and use the
smart pointer types it creates for you.
Visual C++ then creates two files which it automagically
#includes in your compilation. They're stored in your
output directory and are named with the same base name as the type
library with the extensions ".TLH" and ".TLI."
For instance, our program has the #import:
#import "..\NonATLObject.tlb"
and it generates two files in the output directory (DEBUG for debug
builds), NonATLObject.TLH and
NonATLObject.TLI.
What #import generates
You don't need to know what's in these files, but the good doctor knows well that you won't be comfortable using the COM smart pointers unless you know what they do. So, for his patients who insist on knowing the truth, here's what's going on under the hood.
By default, the .TLH file contains declarations of the
following:
structdeclarations withdeclspec(uuid("<GUID goes here>"))declarations to associate a GUID with the class and each interface. This allows you to use theuuidofoperator to retrieve the GUID of the class and each of its interfaces, as in__uuidof(MyClass).
- Smart pointer definitions for each interface pointer using the
COM_SMARTPTR_TYPEDEFmacro. These smart pointers handleAddRef,Release, andQueryInterfacecalls for us automatically. In addition, they allow us to create objects without explicitly callingCoCreateInstance. The declaration for the smart pointer for theIFoointerface is:_COM_SMARTPTR_TYPEDEF(IFoo, uuidof(IFoo));
which the compiler expands to:
typedef _com_ptr_t<_com_IIID<IFoo, __uuidof(IFoo)> > IFooPtr;
thus generating a new smart pointer class called
IFooPtr based on the com_ptr_t template class.
This pointer class automatically handles CoCreateInstance
and all of the IUnknown functionality. (Look up
com_ptr_t in online help for details on this template.)
- Interface declarations for each interface which include raw and
error-checked wrappers for all of the methods and properties on the
interface. (We have no properties in our example, but if we did, we
could use them as easily and directly as we do in Visual Basic by
using the property name itself. The compiler generates the property
with a special
declspec, generates the appropriate get and set methods, and converts uses of the property such as "pIFoo->Prop1 = 5;" into the appropriateGetXxxorSetXxxmethod calls.)The error-checked wrappers check the
HRESULTfor errors and throw acom_errorexception if theHRESULTindicates an error.So our
IFoodeclaration is as follows:struct __declspec(uuid("7ba998d0-c34f-11d1-a54d-0000f8751ba7")) IFoo : IUnknown { // Wrapper methods for error-handling HRESULT Func1 ( ); HRESULT Func2 ( int inonly ); // Raw methods provided by interface virtual HRESULT __stdcall raw_Func1 ( ) = 0; virtual HRESULT __stdcall raw_Func2 ( int inonly ) = 0; };
Note that the .TLH "renames" the real
interface functions by prepending "raw_" to the names. It
is the raw functions that actually map to the interface – they're the only
pure virtual functions. The wrappers will call the raw functions.
All of these declarations will be in a C++ namespace with the same
name as the LIBRARY name in your typelib. Note that these
names are case-sensitive, as are all identifiers in C++. You can either
qualify each use of an identifier by using the typelib name, as in:
NONATLOBJECTLib::IFooPtr *pIFoo;
or you can use the using namespace directive to make the
identifiers you imported accessible, as in:
using namespace NONATLOBJECTLib;
// later, but in same scope...
IFooPtr *pIFoo;
The using namespace directive obeys the usual scope
rules, so it's handiest – it eliminates the need to type the namespace
name repeatedly and you can use it within blocks to limit its scope. Dr.
GUI doesn't recommend using the no_namespace modifier on
the #import statement since it can cause name conflicts if
you use multiple typelibs.
You may have noted that there are a lot of specific
defaults – exception handling, namespaces, wrapper functions, and so on.
These defaults are the handiest, but if you don't like 'em you can
easily change the way the code is generated for you by using one or more
of the myriad attributes of the #import directive. So you
can make your code as quick and easy or as lean and mean as you want.
Check the online help for #import for details.
By comparison to the .TLH file, the .TLI
file is boring: it simply contains implementations for the wrapper
functions. For instance, for our IFoo interface, it
contains the wrappers that call the raw interface function and throw an
exception if the HRESULT indicates and error:
inline HRESULT IFoo::Func1 ( ) {
HRESULT _hr = raw_Func1();
if (FAILED(_hr))
_com_issue_errorex(_hr, this, __uuidof(this));
return _hr;
}
inline HRESULT IFoo::Func2 ( int inonly ) {
HRESULT _hr = raw_Func2(inonly);
if (FAILED(_hr))
_com_issue_errorex(_hr, this, __uuidof(this));
return _hr;
}Creating and Using Our COM Object with COM Smart Pointers
Creating and using our COM object almost couldn't be easier. The steps are the same as before, but they're all simpler – and our error handling can be consolidated into one exception-handling block.
#import-ing the type library and initializing COM
First, we do the necessary #import directive to give the
compiler access to the type library.
Next, we need to make sure that the COM library is initialized by
calling CoInitialize or CoInitializeEx. (In
Dr. GUI's case, he called AfxOleInit since he wrote his
test app using MFC. Note that the COM smart pointers are compatible with
MFC applications.)
Creating the object
Creating the object is very simple: we just create a smart pointer
and pass the GUID of the object we want to create to an overload of its
constructor. The overload that takes a GUID as a parameter automatically
calls CoCreateInstance for us:
IFooPtr pIFoo(__uuidof(MyObject));
Don't forget about the namespace – you'll want to use the appropriate
using the namespace Xxx; directive so you can use the types
declared by #import.
Calling methods and accessing properties
Once the object is created, we can call its methods. The syntax is just as we expect:
pIFoo->Func1();
pIFoo->Func2(5);
If we had properties in our interface (we've not discussed this much yet), we could also manipulate them directly:
pIFoo->Prop1 = 5; // calls Set method
int a = pIFoo->Prop2; // calls Get method
The compiler automatically changes the property references to the
appropriate function calls. Properties are declared in the interface
structure in the .TLI file with a special
__declspec.
Catching exceptions
Note that any of the operations on the object, even creating it, can
fail. By default, a com_error exception is thrown if
anything goes wrong. We should use a try/catch block to
catch any exceptions:
try {
IFooPtr pIFoo(__uuidof(MyObject));
pIFoo->Func1();
}
catch (_com_error e) {
AfxMessageBox(e.ErrorMessage());
}
Using exception handling makes your code clear and easy to
understand, but note that using it involves some size and speed costs.
Generally, these costs are worth it compared to the code you'd have to
write otherwise (remember the nasty nested ifs and
gotos we had before?), but good programmers know what
features cost so they can make a rational decision about whether to use
them. To get an idea of the costs, look at the assembly code generated
for a small test program. Compare that with the maze of error checking
you'd have to do otherwise – you may find that using exceptions is not all
that much worse than doing the error checking yourself – and much more
convenient.
Using a different interface
Using a different interface is also very easy: just create a new
pointer of the new interface type and initialize it with another smart
interface pointer or assign the old smart pointer to it. The constructor
or assignment operator automatically calls QueryInterface
for you. (If this fails, an exception will be thrown.) For instance, you
could write:
IGooPtr pIGoo(__uuidof(MyObject)); // create object
pIGoo->Gunc(); // call method
IFooPtr pIFoo = pIGoo; // QI different interface, same object
pIFoo->Func1(); // call method on new interface
In this case, the IFooPtr constructor that takes a smart
pointer as a parameter calls QueryInterface for you. If it
fails, an exception will be thrown.
Uninitializing COM
Dr. GUI's program doesn't need to explicitly uninitialize COM – MFC
will do it. But if you're not using MFC, you'll need to have a matching
CoUninitialize call for each call you make to
CoInitialize or CoInitializeEx.
It Almost Couldn't Be Easier
As you see, using the COM smart pointers makes using COM objects from C++ as easy as using them from Visual Basic. And the implementation of COM smart pointers comes at a small cost in efficiency – in most cases, the value of clearer code, fewer hassles, and more consistent error checking far outweighs the relatively small costs.
Where We've Been; Where We're Going
This time, we showed how to use the new Visual C++ 5.0 smart COM pointer class to make using COM objects as easy as in Visual Basic. Next time, we'll start with ATL by learning about the "T" in ATL: C++ templates.
Your turn
Do you have any topics you'd like to see the good doctor address? You can write the Doc at drgui@microsoft.com. Although the good doctor's surgery schedule precludes individual replies, Dr. GUI does read and consider all mail.